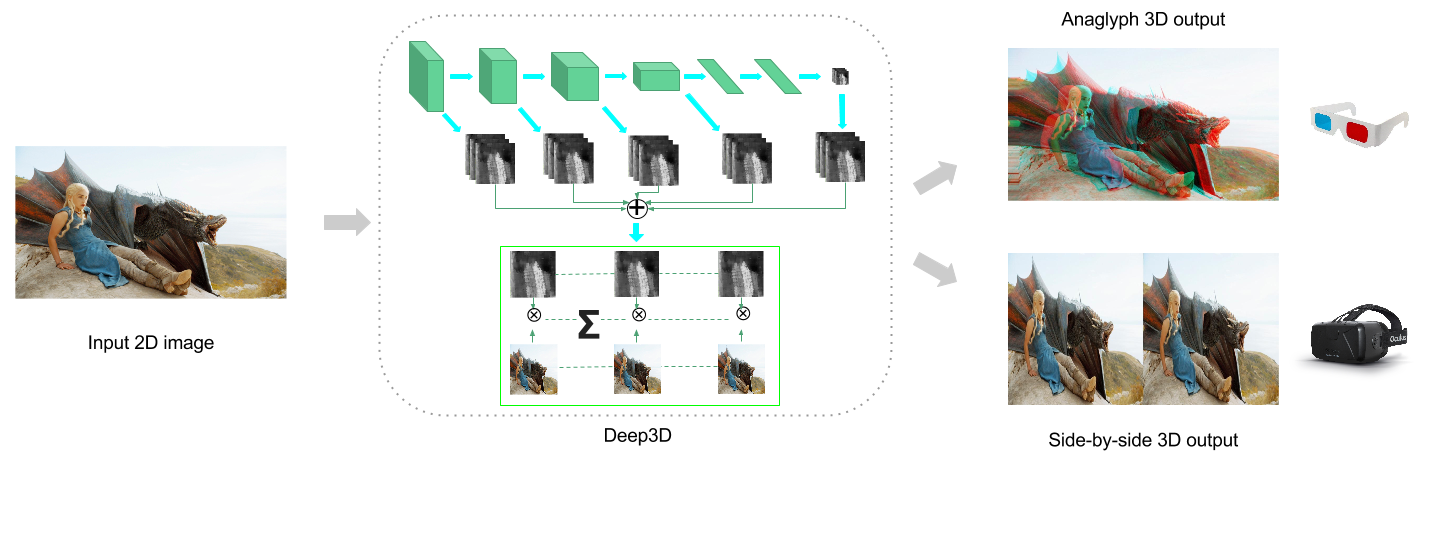
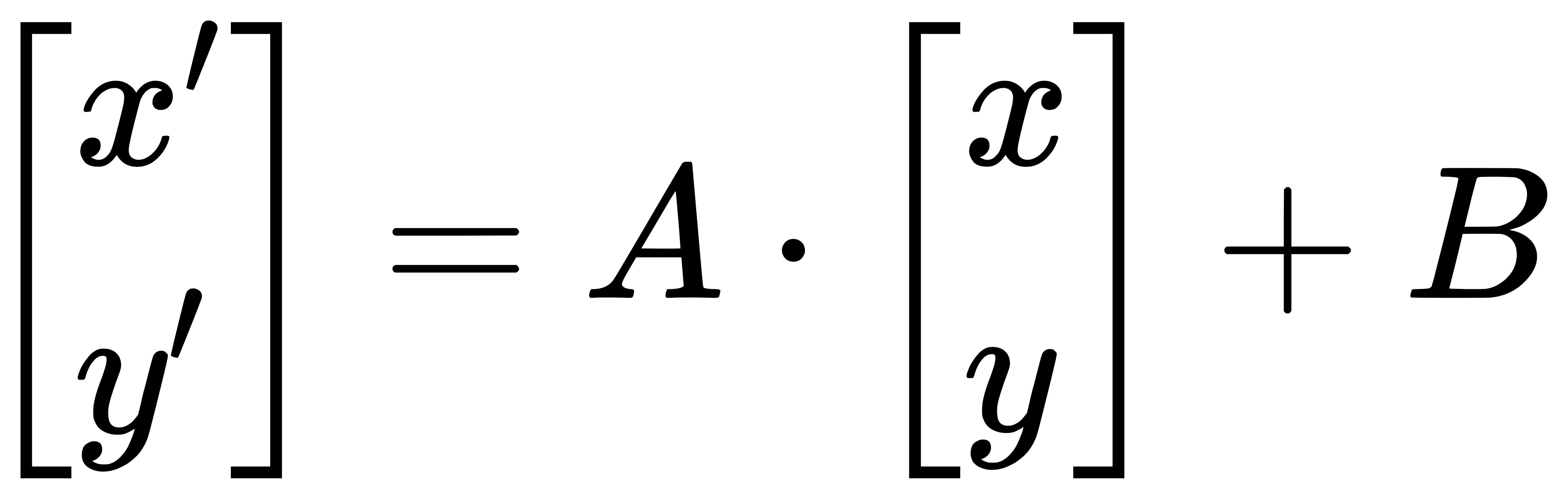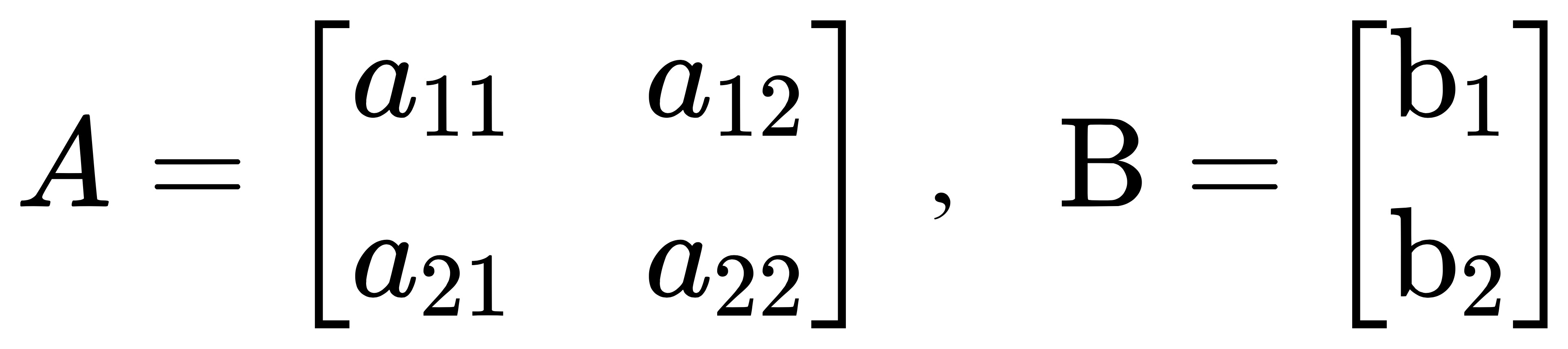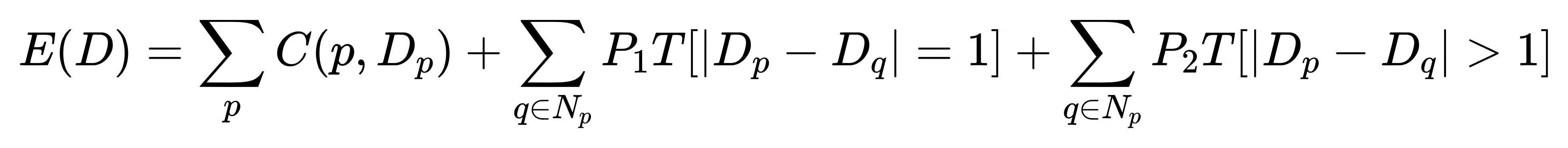人脸识别之人脸矫正
一般来说,使用 mtcnn 网络检测到人脸后,都需要进行矫正。而对于人脸矫正,最简单的可以通过使用仿射变换来实现。

武汉疫情还没过去,这几天窝在家里琢磨了下 TensorFlow 的多卡 GPU 分布式训练的机制。本文将使用流行的 MNIST 数据集上训练一个 MobileNetV2 模型,并利用 tf.distribute.Strategy 函数实现多卡 GPU 对训练方式。 详细代码见 TensorFlow2.0-Example

2020 年春节将至,大部分同事已经回家。回顾下自己的 2019,似乎收获颇丰:不仅顺利毕业,还找了份谋生的工作。这期间看了很多复杂的算法,有监督 or 无监督,目标检测 or 深度估计。而人一旦徜徉在其中,就会渐渐忘记一些基础的东西。是时候回顾一下梯度下降法了….
问题:请尝试使用梯度下降法求解 sqrt{2020} 的值,并精确到小数点后 4 位。
双目相机通过同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。一旦我们获取了物体在图像上的每个像素深度,我们便能重构出一些它的三维信息。

双目相机一般由左眼和右眼两个水平放置的相机组成,其距离称为双目相机的基线(Baseline, 记作 b),是双目的重要参数。由于左右两个相机之间有一定距离,因此同一个物体在左右图上的横坐标会有一些差异,称为视差(Disparity)。
目前制作 3D 电影的方法有两种:一种是直接用昂贵的立体相机设备进行拍摄,这种制作成本非常庞大。另一种则是通过图像处理技术将 2D 电影转化成 3D 格式,这种转换处理通常依赖于“深度艺术家”,他们手工地为每一帧创造深度图,然后利用标准的基于深度图像的渲染算法将与原始图像相结合,得到一个立体的图像对,这需要大量的人力成本。现在来说,每年只有 20 左右部新的 3D 电影发行。