UnitBox:一种新的 IoU 损失函数,把 box 当作一个整体去预测
这篇论文注意到了一个大多数人没有注意到的问题:现在很多目标检测都是将物体的边框看作四个独立的变量,使用 L1 或 L2 loss 对其分别进行回归,但是这样获得的检测精度其实有限,因为它忽略了物体的尺度和形状等因素。
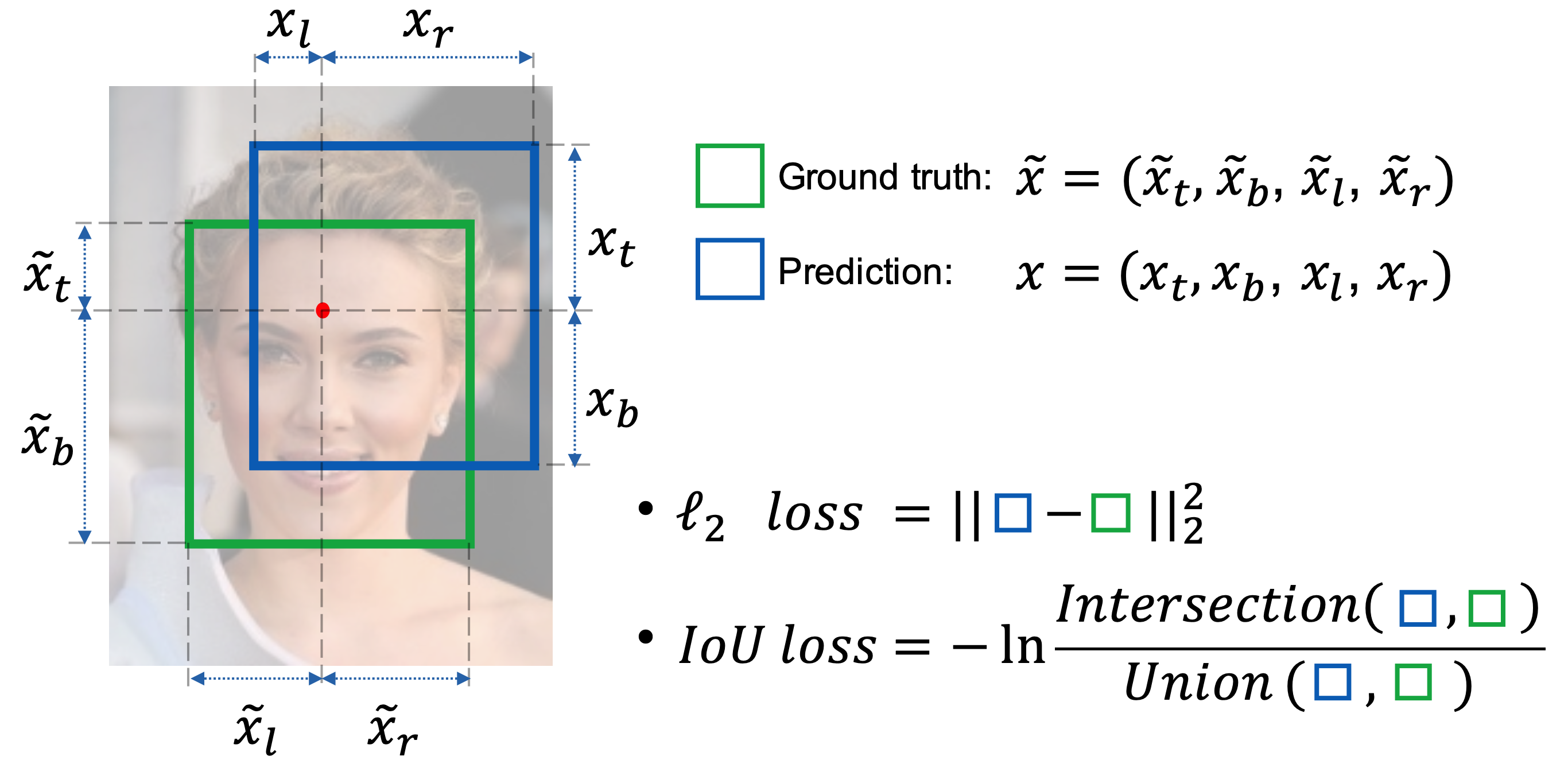
比如大目标的尺度较大,所以它的 L2 损失可能会比小目标相对更大一些,但是这并不意味着它就预测得比小目标更差。像下面这幅图里,小目标的 loss 低,但是它反而预测得没有大目标好。

作者就想到把 box 看作一个整体,考虑到 IoU ∈ [0, 1] 范围内,那么 L = - In(IoU) 其实就相当于 ground-truth 框和预测框之间的交叉熵损失。不妨将 IoU 看成是采样于伯努利分布(Bernoulli distribution)的一种随机变量,p(IoU=1)=1,它描述了预测框成为真实框的概率分布,因此得到交叉熵损失如下:
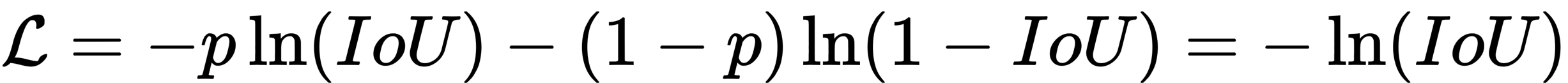
与 L2 Loss相比,IoU Loss 将边框视为一个整体,并且不论方框的尺度大小,因此预测结果会比 L2 Loss的更加精确。