讲一讲目前深度学习下基于单目的三维人体重建技术
近年来,基于深度学习的单目三维人体重建技术已经取得了巨大的进展。特别是基于马普所的 SMPL 参数化人体模型这块,今天就来简单聊聊这一系列的相关工作。

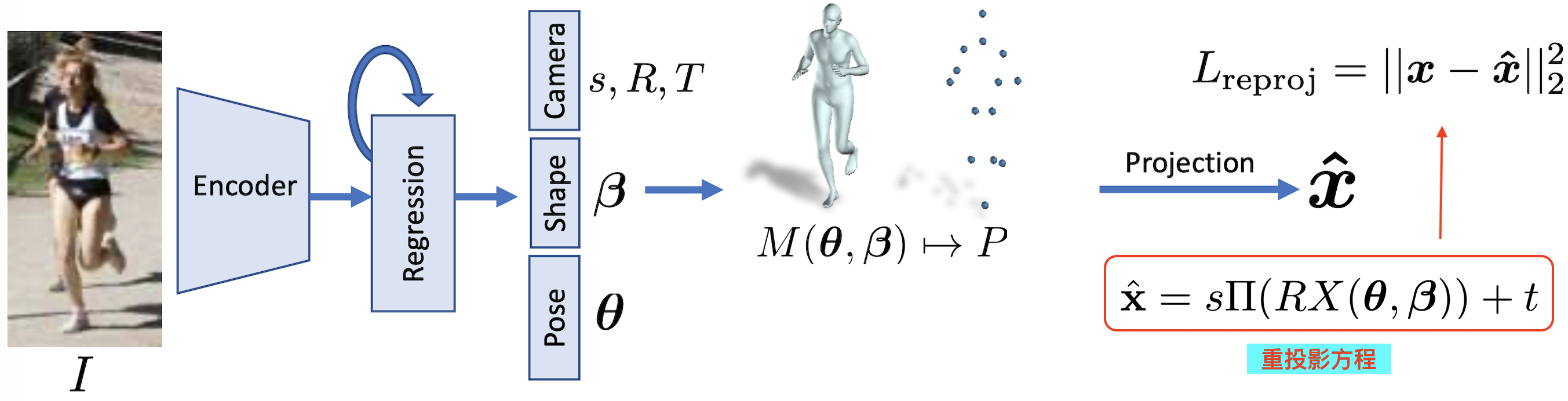
如上图所示,给定一张 RGB 图片,我们希望恢复出图中人体的姿态和形状等信息。从前面讲的 SMPL 参数化人体模型可知,我们只需要估计出数字人体模型的相关参数即可。例如在 HMR 算法中,则需要预测出 23x3 + 10 + 2 + 1 + 3 = 85 个参数:
- 23 个关节点的 pose 参数,每个参数由轴角表示(axis-angle representation)
- 10 个人体形状 shape 参数
- 相机外参数 t (图像平面上的 2D 平移)和缩放尺度 s 以及根结点的旋转轴角 R
对这些参数直接回归是比较困难的,所以网络预测的是相对于初始 SMPL 参数的偏移量。一般是通过两层全连接网络作为回归器 Regressor 输出偏移量,然后再与预测的 SMPL 参数拼接相加然后继续迭代 3 次得到。
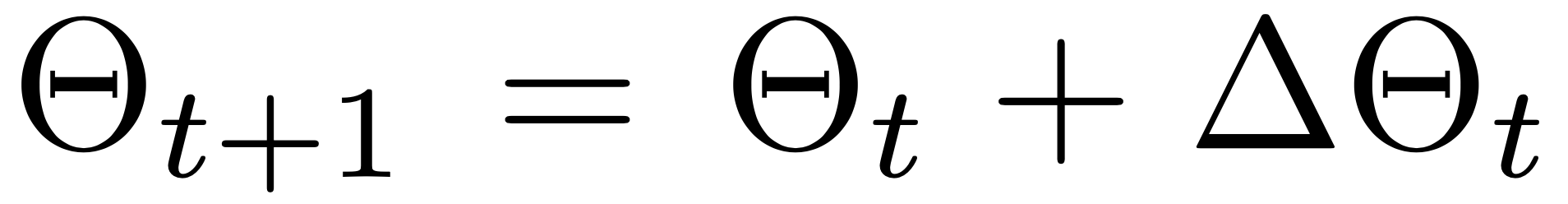
pred_pose = init_pose |
考虑到目前业界里 3D 动捕数据的稀缺性,而目前市面上能获得很多人工标注的 2D 关键点数据集(比如 COCO 和 PoseTrack 等)。因此会引入 3D -> 2D 的重投影损失(reprojection loss),即将 SMPL 人体的 3D 关键点投影到 2D 图像上与人工标注的 2D 关节点计算损失。
# 定义 2D 关键点的损失函数 |
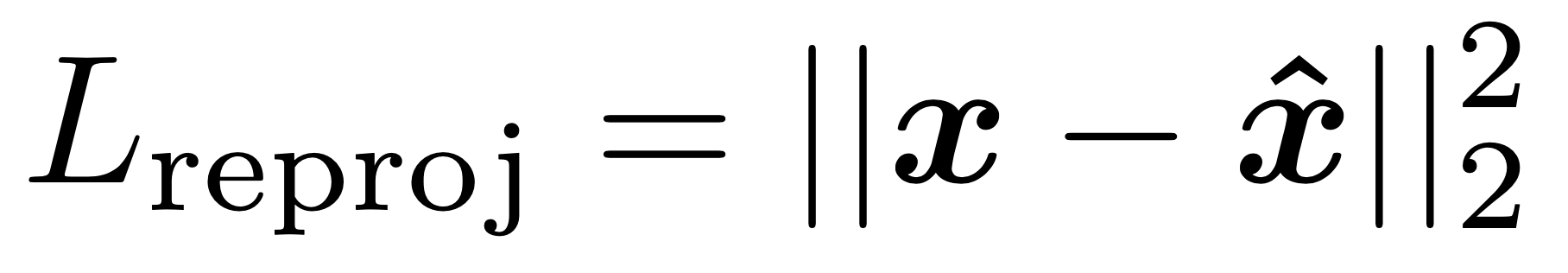
尽管 3D 数据集比较难获得,但是 3D 关键点损失也要考虑在内。它的损失函数与 2D 关键点损失一样,都是 nn.MSELoss 函数,输入则为 24 (23+1)个关键点的 3D 标注坐标和预测坐标。详见 keypoint_3d_loss 损失函数。
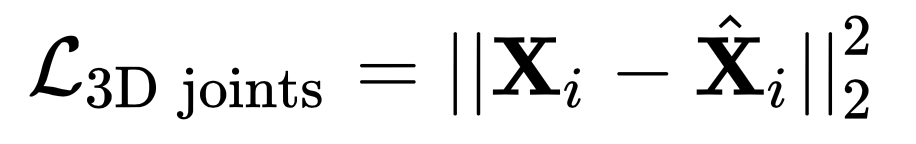
一些数据集如 Human3.6M 不仅能获得人体的 3D 关键点坐标和 pose 信息,还用到了 3D scan 扫描获得人体的 mesh 信息。我们可以通过使用 Mosh 工具将这些标注数据转化成 SMPL 的(β,θ)参数,然后对它们直接进行监督,详见 smpl_losses 损失函数。
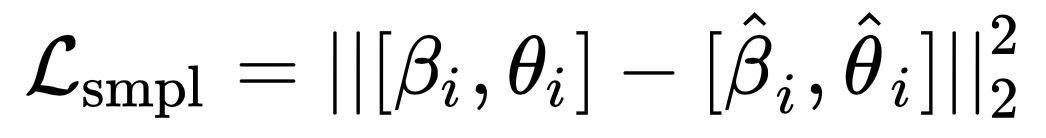
# 使用 MSELoss 损失函数 |
如果你觉得光靠上面几种监督方式就能实现很好地对人体三维重建,那就大错特错了。尽管人体的 2D 关键点可能预测得很准,但是由于深度的模糊性和人体关节点的自由度比较大,所以模型预测的人体姿态很容易发生扭曲,而这种扭曲形态显然是正常人类无法做到的。

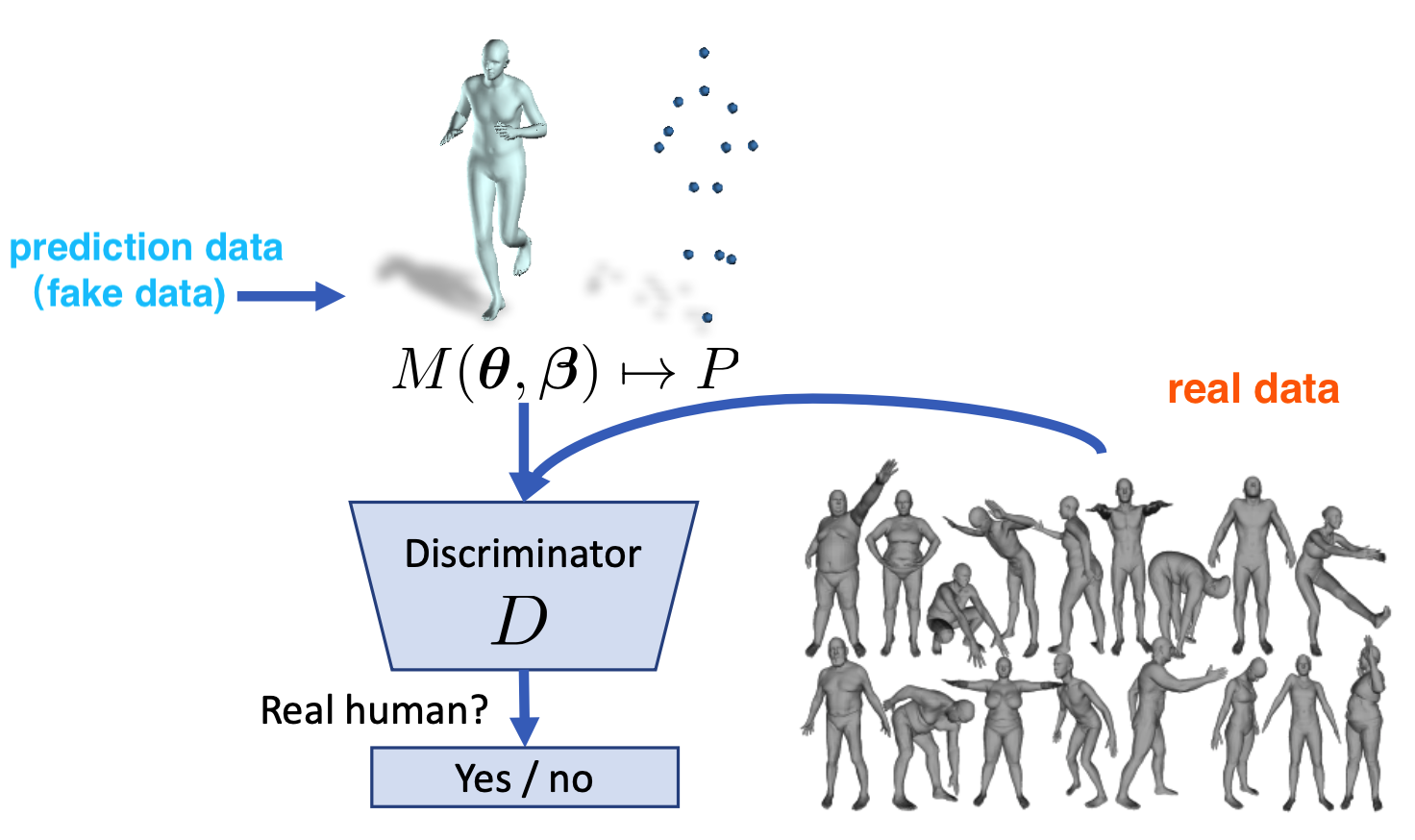
常用的方法是使用判别器(discriminator)对模型输出的(β,θ)参数进行监督,用来判断是否属于真实人体。在 HMR 算法中,一共使用了 K+2 个判别器,K 指的是人体的关节数目,2 则指的是 SMPL 的 β 和 θ 参数。每个判别器输出的值在 [0, 1] 范围内,代表了参数来源于真实数据的概率。
当我们做到这里的时候已经能达到 SOTA 的效果了,但是在实际的野外场景中应用会发现:我们依然无法捕获到人类实际运动的复杂性和可变性以及准确而又自然的运动序列。在 HMR 预训练模型的基础上,VIBE 算法使用了时序编码器 GRU 来考虑上下帧人体动作的连贯性,并且增加了一个动作判别器(Motion discriminator)来判断生成器输出的人体动作序列是否接近真实人类。

结束语:尽管基于 SMPL 参数的人体三维重建技术取得了一定的成就,但是由于这块领域的开拓的时间其实不是很长,我觉得未来的想象空间依然很大。SMPL 算法其实早在 2015 年就提出来了,但是这块的人体重建算法也就这两年才开始爆发和逐渐成熟。目前基于纯视觉的人体重建技术的阻力依然很大,例如基于室外场景的 3D 标注数据很稀缺、多人场景下的遮挡问题和模型的 real-time 性等,这其中的任何一个子问题都亟待我们去探索和解决。