知识蒸馏:Distilling the Knowledge in a Neural Network
知识蒸馏(Knowledge Distillation,KD),就是将一个大网络学习到的知识通过蒸馏提炼到另一个小网络中去。通常是存在一个已经训练好的、具备知识的成熟 Teacher Model,用它来指导 Student Model 学习。
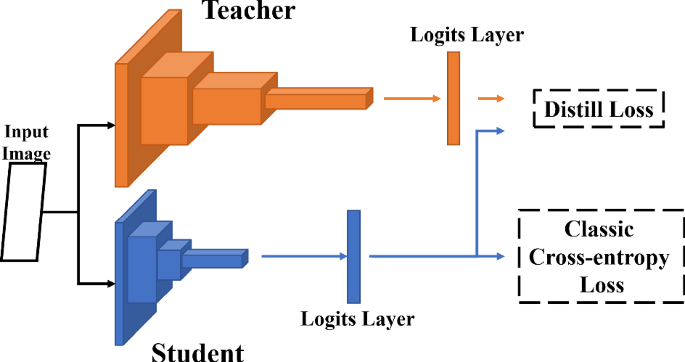
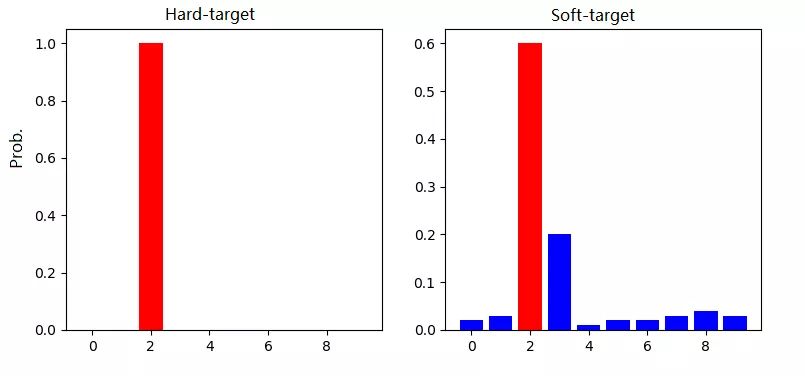
知识蒸馏这个名字第一次是出现在 Hinton 祖师爷的《Distilling the Knowledge in a Neural Network(2015)》 论文里的,它提出可以同时利用真实的 hard target 和教师网络输出的 soft target 对学生网络进行监督训练。hard target 是由原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0,分布比较尖锐。soft target 是经过温度 T 软化后的概率分布,每个类别都分配了概率,但是正标签的概率最高,分布比较平缓。
在训练阶段,教师网络输出的 Logits 除以温度参数 T 后再做 softmax 变换得到软化的概率分布。温度 T 越大,概率分布就越缓和,就越容易放大错误分类的概率而引入不必要的噪声,因此要合理控制 T 参数。在高温 T 蒸馏下,将教师网络的知识传递给学生网络,这个过程通过 soft loss 监督学习;与此同时,还要让学生网络看看 ground truth 标签(老师也不一定全对)计算 hard loss。在测试阶段,学生网络输出的 Logits 不再需要除以温度 T 而是直接送入 soft max 层。
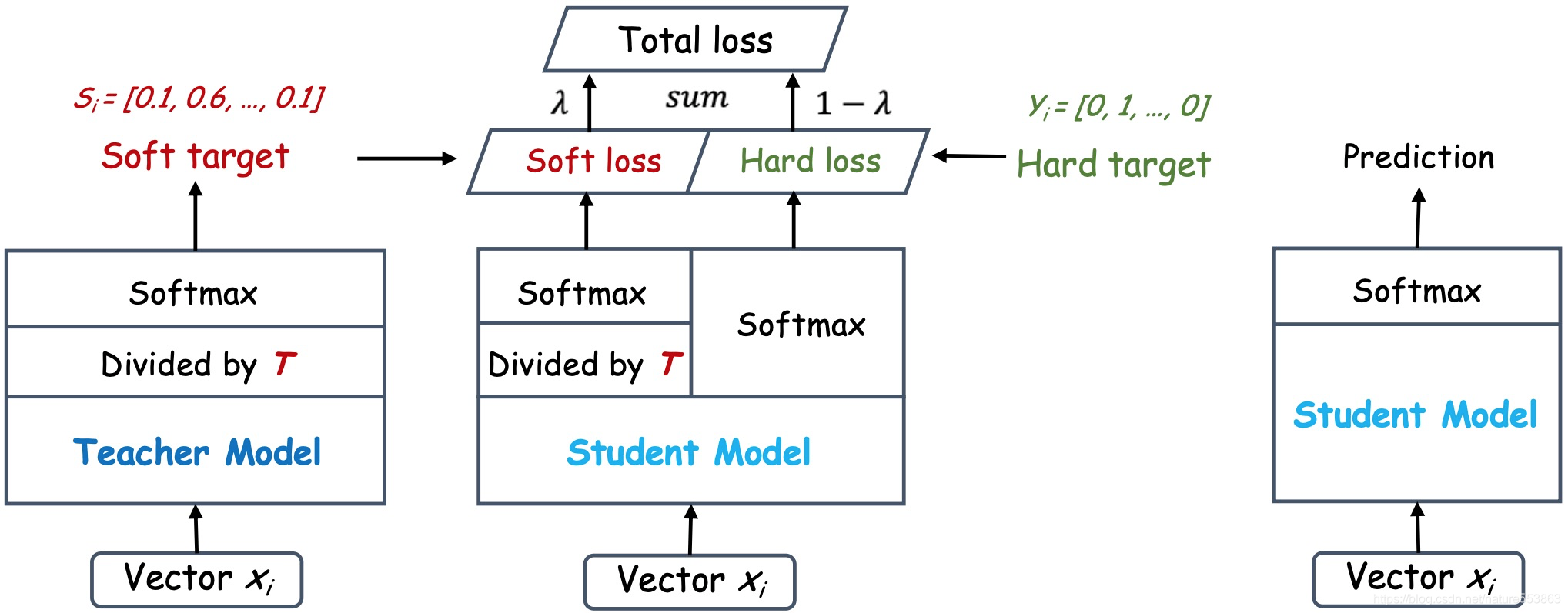
引入一个权重 λ 来权衡两种损失的重要程度,λ 越大,表示对老师的信赖程度越高。通常训练初期会给一个比较大的 λ 值,然后在后期逐渐降低。这就叫,师傅领进门,修行在个人。
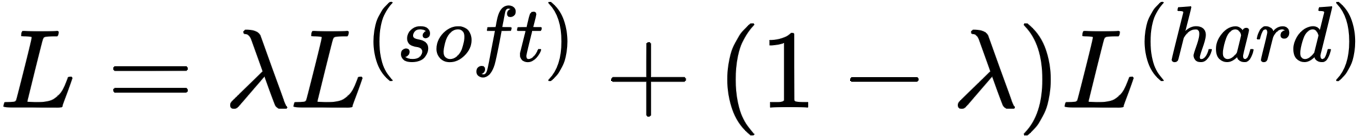
def loss_fn_kd(outputs, labels, teacher_outputs, params): |
至于说知识蒸馏为什么能 work,至今还没有一个定论。目前比较流行的一种说法是,soft target 的信息熵比较高,隐含了不同 label 特征之间的相似性。比如同时分类驴和马的时候,尽管某张图片是马,但是 soft target 就不会像 hard target 那样只有在马的 index 处为 1,其余为 0,而是在驴这里也会给予一定概率。其实也可以这样理解:如果只有正样本的概率为 1 而其他所有负样本的概率为 0 的话,那么就抹平了其他负样本之间的 distance,其实这种 distance 信息是可以通过教师网络事先学习到然后再传递给学生网络。
总结一下:在整个知识蒸馏过程中,我们先让温度 T 升高,然后在测试阶段恢复常温( T=1 ),从而将教师模型中的知识提取出来,是为蒸馏。