CenterNet 和 CenterTrack:以点代物,同时进行目标检测和跟踪
在 CornerNet 使用角点框出目标后,就自然会想到直接用中心点检测目标。CenterNet 提出一种新的检测思路:把目标看成一个点,它的一些性质如尺寸、3D 坐标、朝向和关键点能直接回归得到,并且还不需要 nms 过程。
既然目标已经用一个点来代替了,那么能不能按时间顺序去跟踪这个中心点?依旧是同样的配方、熟悉的团队,提出了一个基于中心点的联合检测与跟踪框架 —— CenterTrack

1. CenterNet
和 CornerNet 一样,作者也是通过二维高斯热图的方式去预测关键点,输出的热图 shape 为 [C, H, W]。如果物体属于该类别,其中心点位置对应的概率为 1,其他类别为 0,而对于远离中心点的像素概率随着二维高斯分布衰减。如果出现两个高斯分布发生重叠,那么直接取元素间最大值的就行。

对于 heatmap 的损失函数,作者也采用了 focal loss 来处理难易样本不均衡的问题。由于 CenterNet 只会对每个物体预测出一个正样本(只选择概率最高的),因此就不需要非极大值抑制过程了,大大简化了目标检测的后处理流程。对于物体中心位置,这里也是和 CornerNet 一样使用的是 offset prediction 方式。
对每个目标的尺寸 s = (xmax - xmin, ymax - ymin),它这里是直接进行回归的(因为没有 anchor,所以无法回归偏移量)同样是采用 L1 损失函数。需要说明的是,预测框的 offset 损失和 size 损失都是只考虑正样本的。CenterNet 最终输出的 feature map 的维度为 [C+4,H,W],C 指的是类别概率,4 分别指的是中心位置的 offset 和 bbox 尺寸。

其他就没什么讲的了,可能是为了凑工作量吧,作者对目标的属性预测延伸到了深度、3D 位置和肢体关键点检测,但是这方面的工作都没有让人眼前特别一亮的感觉 😂。
| 其实像 CenterNet 这种直接回归目标中心位置的偏移量和尺寸的思路,YOLOv1 早在 2015 年就已经这样做过了。但是由于当时 YOLOv1 没有采用高斯热图这种方式,导致正样本只有物体中心这一个点,使得它的召回率特别低。在时代的局限性下,Joseph Redmon 只好在 YOLOv2 中采用了 anchor-base 机制。 |
2. CenterTrack
CenterTrack 的思想比较简洁:直接预测相邻两帧同一物体在图像上的 2D 位移,然后通过它们之间的距离去判断两个 detection 是否是属于同一个物体。 CenterTrack 的网络结构和 CenterNet 基本一致,只不过输入和输出有些差别。如下图所示:CenterTrack 输入当前帧与前一帧 ➕ 一张heatmap图,然后输出当前帧的高斯热图、目标 size 和相对前一帧的位移。
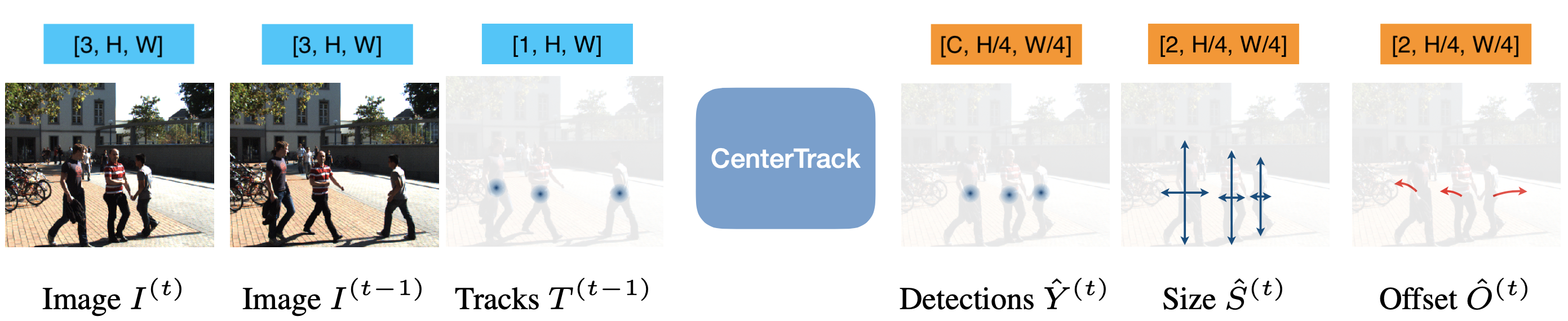
对于预测位移 offset 的损失函数,和 CenterNet 一样使用的也是 L1 损失函数。中心点的位移量 d 预测好了以后,可以通过简单的贪婪匹配算法实现跨时间关联目标。 对于当前位置 p 的检测结果,可以与上一帧位于 p-d 附近的检测结果相关联,并且以置信度进行降序排列。如果在半径 κ 范围内没有匹配上,则生成一个新的跟踪片(tracklet),其中 κ 定义为每个跟踪片所对应预测框的宽度和高度的几何平均值。
CenterTrack 实现了 end-to-end 的训练方式,并且在性能和速度方面也达到了 SOTA 的效果。但是它的缺点也很明显:因为它只能关联连续两帧之间的检测框,所以无法重新激活那些消失较长时间的目标,期待后面的工作能对此进行改进吧。