卡尔曼滤波算法,永远滴神!
鲁道夫 • 卡尔曼在一次访问 NASA 埃姆斯研究中心时,发现他的卡尔曼滤波算法能帮助解决阿波罗计划的轨道预测问题,最终,飞船正确驶向月球,完成了人类历史上的第一次登月。卡尔曼因而一举成名,后来还被美国总统奥巴马授予了国家科学勋章。

1. 阿波罗登月
让我们来想象一下阿波罗登月这个不可思议的神话:当飞行器飞向太空时,会不停地用各种传感器来测量自己的位置,希望自己在预定轨道上。但由于传感器的噪声影响,虽然它一直在测量和调整,但仍有可能慢慢偏离预定轨道。我们需要做的是,过滤掉那些噪声,估算出飞行器正确的位置。
我们先尝试下使用 S-G 滤波器(Savitzky–Golay filter),它的核心思想是对一定长度窗口内的数据点进行 k 阶多项式拟合,其加权系数是通过在滑动窗口内对给定高阶多项式的最小二乘拟合得出。下面写了一段程序模拟 S-G 滤波器是如何实时处理一段噪声数据的:
import numpy as np |
上述程序中提供了 100 帧带有正态分布噪声的数据,我们需要 S-G 滤波器对它们进行实时处理。由于窗口 size 设置成了 5,我们首先缓存了前 5 帧数据并对它们不进行任何平滑处理。等遍历到第 6 帧数据时,我们使用 savgol_filter 计算出缓存队列里经过平滑后的数据,并取出缓存队列中间的数据。为了保证滑动窗口(即缓存队列)的长度不变,在整个过程中我们需要不停地 push 数据和 pop 数据。整个滑动过程类似于下图所示:
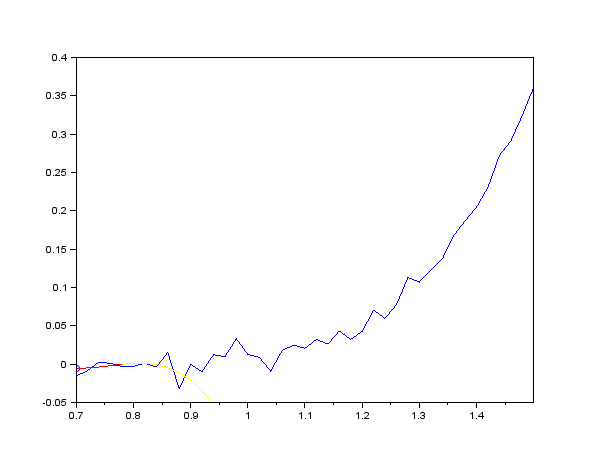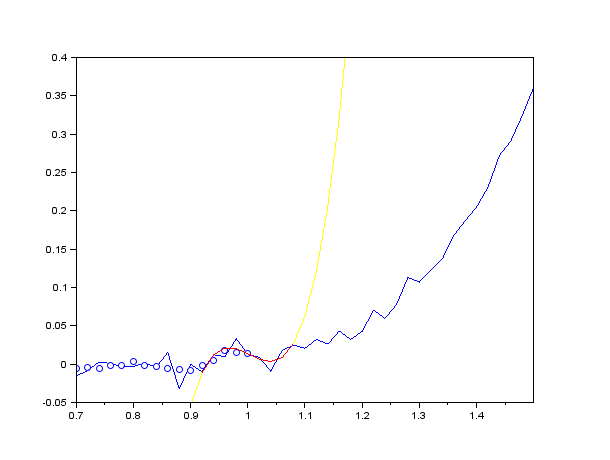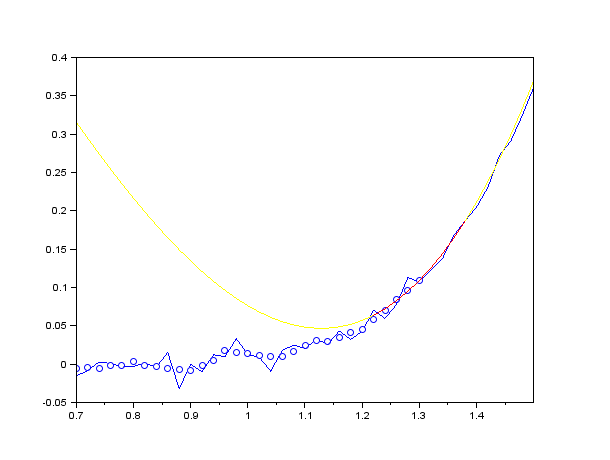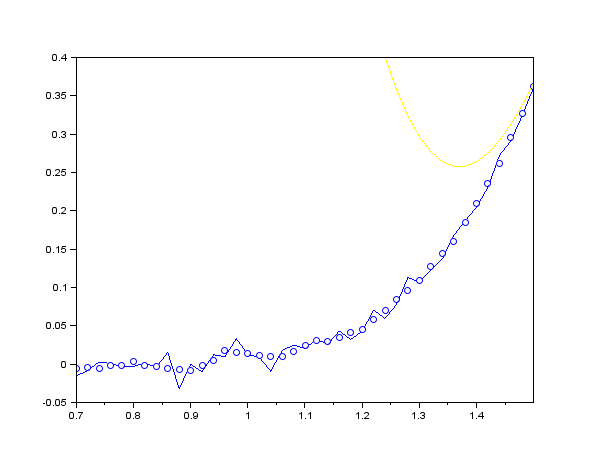
观察这个过程,发现有个非常严重的 bug:被平滑的数据需要依赖前几帧,也就是说 S-G 滤波具有一定的滞后性,比如说如果 window_size = 5,那么就会滞后 2 帧。这里截取一帧并放大显示(红色曲线表示的是滑动窗口):
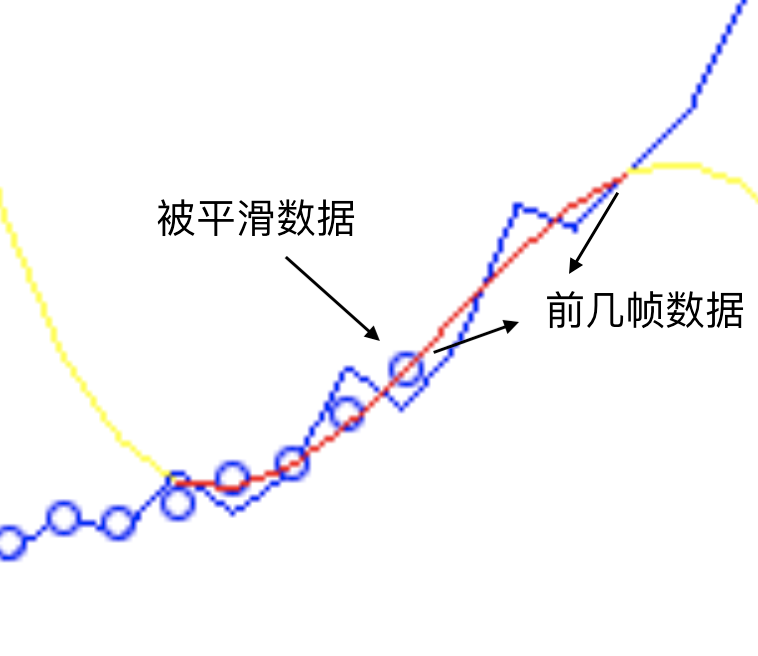
而卡尔曼滤波可以较好地解决这个问题的痛点,它只要获知上一时刻状态的估计值以及当前状态的观测值就可以计算出当前状态的估计值,因此不需要记录观测或者估计的历史信息。在讲卡尔曼滤波之前,我们先来了解两个例子:
2. 两个例子
2.1 例子1 – 金条重量
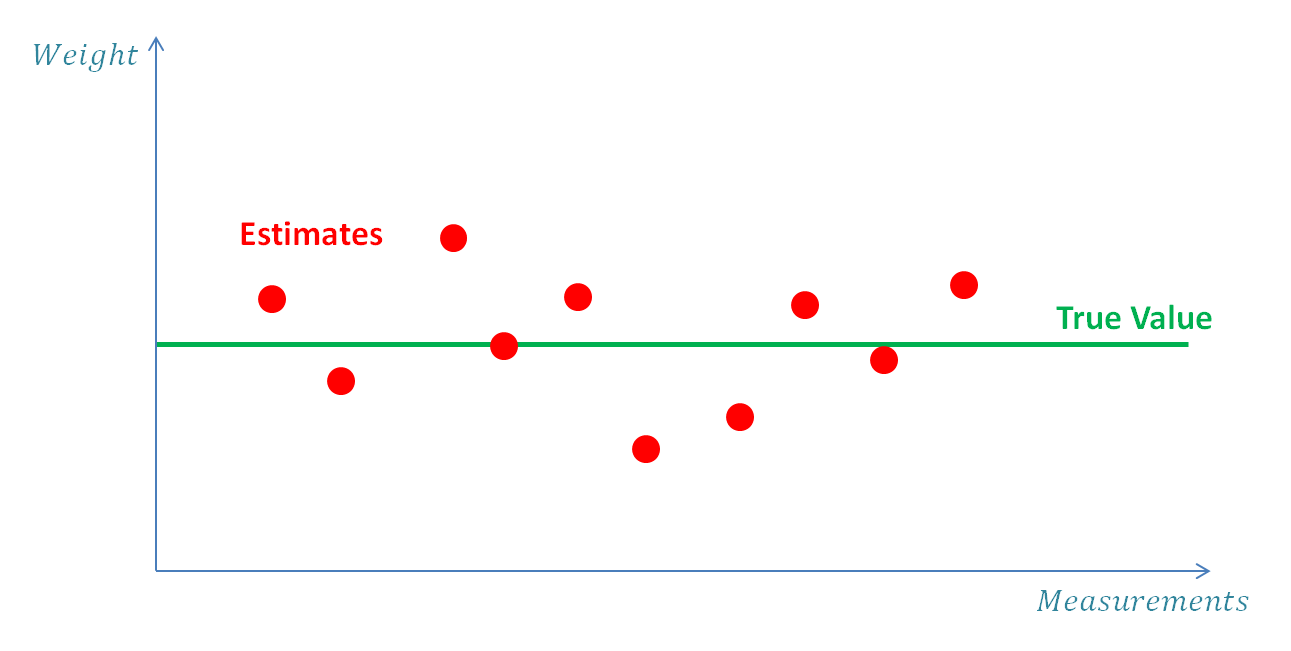
在本例中,我们将估计金条的重量。我们将使用一个无偏秤,也就是说,它没有系统误差,但每次称重会伴随着随机噪声。

在本例中,系统是金条,系统的状态就是金条的重量。假设金条的重量在短时间内不发生变化,即系统的动态模型是恒定的。为了估计系统的状态(金条的重量),可以进行多次测量并求平均值。
经过 N 次测量,其估计值是所有测量值的平均值:

在上面方程式中,我们需要记住所有历史测量数据。假设我们没有笔和纸来记录,也不能凭的记忆记下所有的历史测量数据。但我们可以仅用上一次的估计值和一点小小的调整(在现实生活的应用中,我们想节省计算机内存),以及一个数学小技巧来做到这一点:

上述方程是卡尔曼滤波五个方程之一,名为状态更新 State Update Equation。其含义为:

因此,状态更新方程为:

让我们继续看这个例子,在进行第一次测量前需要预设一个初始猜测值,这个值不用很精准。下面为比较详细的计算过程:
- 第 0 次预测:
我们对金条重量的初步估计是1000克。滤波器初始化操作仅需一次,不会用在下一次迭代中。

状态的下一个估计值(预测值)等于初始值:
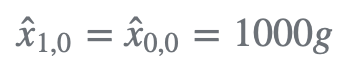
- 第 1 次预测:
第一次秤重:
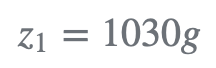
计算卡尔曼增益:
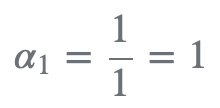
用状态更新方程计算当前估计值:

在这个特定的例子中,最初的猜测可以是任何值,因为 α1=1,初始猜测值在第一次迭代就被消去了。
状态的下一个估计值(预测值)等于当前的估计值:
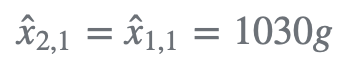
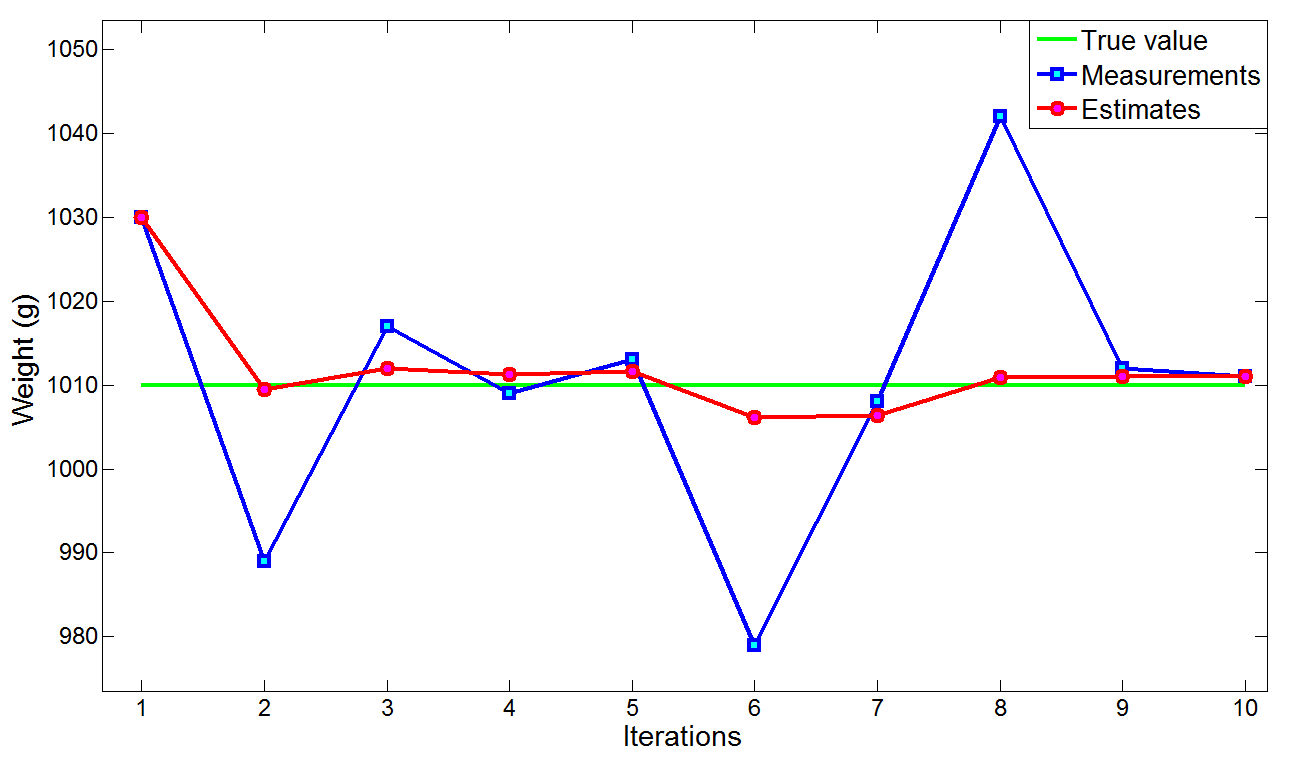
上述过程一直进行到第 10 次预测,下图比较了测量值、估计值和真实值。
2.2 例子2 – 飞行器位置
假设在一个一维空间,有一架飞行器正在向远离雷达的方向飞行。在一维空间中,雷达的角度不变,飞行器的高度不变,如下图所示。
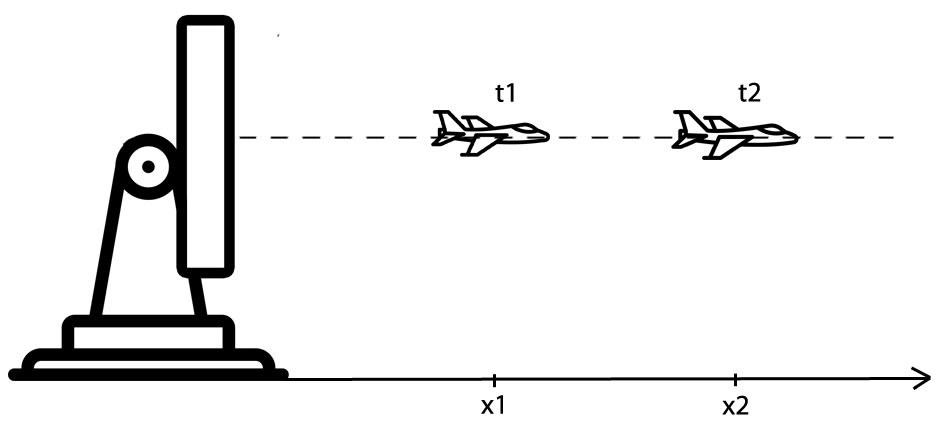
已知前面 N 个时刻飞机的位置,并且雷达已经测量到了此刻飞机的位置,那么我们如何估算出此刻飞机真正的位置呢?
- 方法 1:使用雷达的测量值,但是雷达一般都有一定的系统误差怎么办。
- 方法 2:利用这个时间点之前的所有数据,预测这个时间点的数据。当然,这个预测值也是不准的。
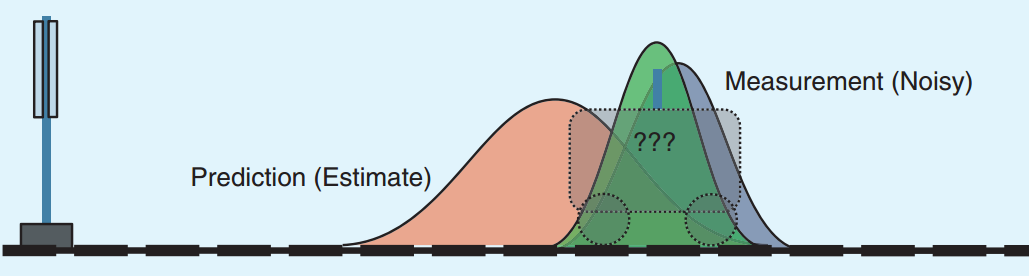
这两种方法告诉了我们不同的答案,两种方法都有一定的可信度。那能否将两种答案相融合呢,卡尔曼滤波就是做了这样的事情。如下图所示,假设两种方法的误差都满足正态分布,如下图所示。如果正态分布越尖锐陡峭,则说明这种方法的预测结果越可信;如果越缓和平坦,则说明越不可信。为了融合这两种方法的预测结果,我们给这两种分布分别赋予一个权重,该权重代表了这个分布对融合结果的重要性。经过融合后的分布变得比之前两种分布更加尖锐,这表明结果更加可信了。
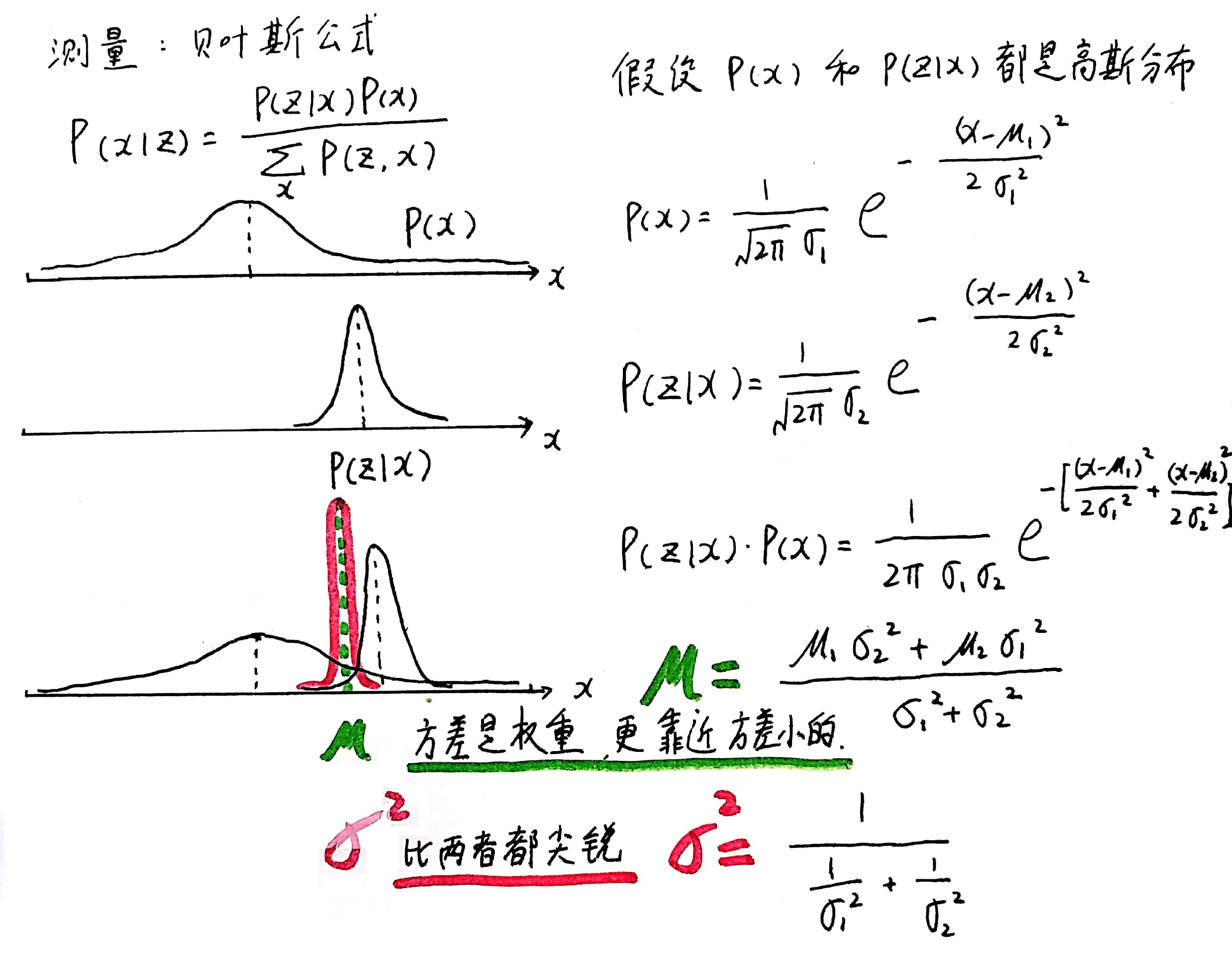
那么如何给出一个合理的权重分布呢,这就是卡尔曼滤波要做的事情。
3. 卡尔曼滤波模型
3.1 Kalman filter 的数学表示
Kalman 滤波分为 2 个步骤,预测(predict)和校正(correct)。预测是基于上一时刻状态估计当前时刻状态,而校正则是综合当前时刻的估计状态与观测状态,估计出最优的状态。预测与校正的过程如下:
- 预测:根据上一时刻(k-1 时刻)的后验估计值来估计当前时刻(k时刻)的状态,得到 k 时刻的先验估计值;
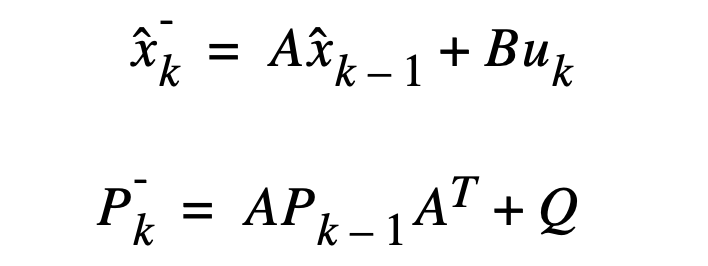
- 校正:使用当前时刻的测量值来校正预测阶段的估计值,得到当前时刻的后验估计值。
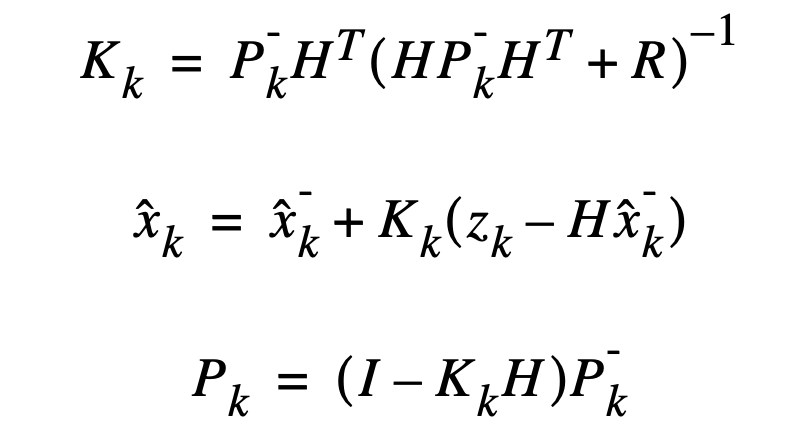

预测阶段负责根据前一时刻的状态估计值来推算当前时刻的状态变量先验估计值和误差协方差先验估计值;校正阶段负责将先验估计和新的测量变量相融合改进的后验估计。卡尔曼滤波算法是一个递归的预测—校正方法,即只要获知上一时刻状态的估计值以及当前状态的观测值就可以计算出当前状态的估计值,因此不需要记录观测或者估计的历史信息。
| 从上面的五个公式中,我们发现:其实卡尔曼滤波的每次迭代更新就是为了求出卡尔曼增益 K,因为它代表了融合估计值和测量值之间的权重。下面这个视频很好地讲解如何通过最小化误差协方差矩阵求出 K: |
视频中的相关推导过程可见 「卡尔曼滤波的理解、推导和应用」
3.2 Python 代码实现
在上面过程中,只有 PQRK 四个矩阵还尚未确定。显然增益矩阵 K 是不需要初始化的,P 是误差矩阵,初始化可以是一个随机的矩阵或者 0,只要经过几次的处理基本上就能调整到正常的水平,因此也就只会影响前面几次的滤波结果。
- Q:预测状态协方差,越小系统越容易收敛,我们对模型预测的值信任度越高;但是太小则容易发散,如果 Q 为零,那么我们只相信预测值;Q 值越大我们对于预测的信任度就越低,而对测量值的信任度就变高;如果 Q 值无穷大,那么我们只信任测量值;
- R:观测状态协方差,如果 R 太大,则表现它对新测量值的信任度降低而更愿意相信预测值,从而使得 kalman 的滤波结果会表现得比较规整和平滑,但是其响应速度会变慢而出现滞后;
- P:误差协方差初始值,表示我们对当前预测状态的信任度。它越小说明我们越相信当前预测状态;它的值决定了初始收敛速度,一般开始设一个较小的值以便于获取较快的收敛速度。随着卡尔曼滤波的迭代,P的值会不断的改变,当系统进入稳态之后P值会收敛成一个最小的估计方差矩阵,这个时候的卡尔曼增益也是最优的,所以这个值只是影响初始收敛速度。
假设系统的真实状态是一条正弦曲线,我们在测量过程中伴随一定正态分布的随机噪声,使用 python 模拟该过程如下:
import numpy as np |

接下来我们使用卡尔曼滤波对这段噪声进行实时去燥和平滑处理:
# allocate space for arrays |
卡尔曼滤波增益 K 值和 Q, R 的比值有关系,而与 Q ,R 的绝对值没有关系。因此我们固定 R 的值为 0.1**2,比较了 Q 分别在 1e-2 和 1e-6 的情况,如下图所示:
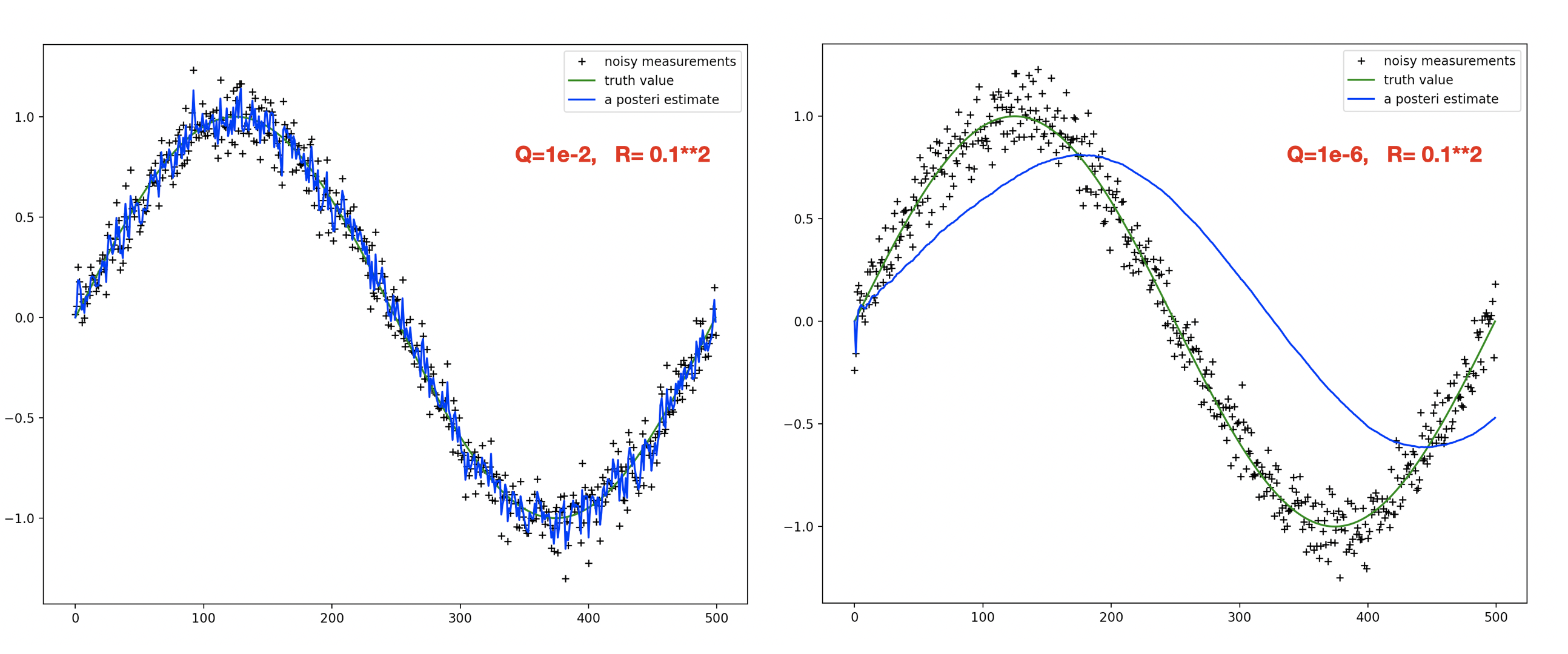
| 从上面的结果可以看出:当 Q 较大时,表明预测状态的方差较大,使得我们比较相信测量值;而当 Q 较小时,我们则比较相信预测值,提高了滤波结果的平滑性,但也增大了滤波结果的滞后性。因此在实际应用中,应当特别注意 Q 和 R 值的选择。 |