随手用 Python 撸一个单目视觉里程计的例子
最近因工作需要,开始接触到一些关于 SLAM(Simultaneous Localization and Mapping)的研究。网上关于 slam 的资料有很多,譬如高博的十四讲,github 上的 VINS 等等。但是他们大多是用 C++ 写的,并且环境依赖复杂。今天, 我使用 Python 手撸了一个简单的单目 slam,对 slam 有了一个初步的认识。完整的代码在这里。
1. ORB 特征点检测
ORB 特征由关键点和描述子两部分组成,它的关键点称为 “Oriented FAST”,是一种改进的 FAST 角点,而描述子则称为 BRIEF。在 OpenCV 中,我们可以这样:
orb = cv2.ORB_create() |

我们首先需要将图片转成灰度图, 然后利用 goodFeaturesToTrack 找出图片中的高质量的角点, 接着使用 orb 里的 compuete 函数计算出这些角点的特征:它会返回 kps 和 des,kps 给出了角点在图像中坐标,而 des 则是这些角点的描述子,一般为 32 维的特征向量。
frame 1: kps[0]=(294.0, 217.0), des[0]=[ 66 245 18 ... 39 206] |
2. 特征点匹配
特征点匹配的意思就是将本帧检测的所有角点和上一帧的角点进行匹配,因此需要将上一帧的角点 last_kps 和描述子 last_des 存储起来。此外还需要 idx 记录每帧的序列号,并且从第二帧才开始做匹配。我们构造了一个 Frame 类,并将它们定义为类的属性,在实例初始化的时候再将这些属性传递给对象。
class Frame(object): |
我直接使用了暴力匹配(Brute-Force)的方法对两帧图片的角点进行配准,通过 cv2.BFMatcher 可以创建一个匹配器 bfmatch,它有两个可选的参数:
normType:度量两个角点之间距离的方式,由于 ORB 是一种基于二进制字符串的描述符,因此可以选择汉明距离 (cv2.NORM_HAMMING)。crossCheck:为布尔变量,默认值为 False。如果设置为 True,匹配条件就会更加严格,只有当两个特征点互相为最佳匹配时才可以。
使用 knnMatch() 可以为每个关键点返回 k 个最佳匹配(将序排列之后取前 k 个),其中 k 是用户自己设定的,这里设置成 k=2。
bfmatch = cv2.BFMatcher(cv2.NORM_HAMMING) |
将 frame.curr_des 、 frame.last_des 和 matches 的数量打印出来:
frame: 16, curr_des: 1660, last_des: 1597, matches: 1660 |
我们发现 matches 的数量始终与 frame.curr_des 相等,这是因为这里是从上一帧 frame.last_des 给当前帧 frame.curr_des 找最佳匹配点,并且每个 match 返回的是 2 个 DMatch 对象,它们具有以下属性:
DMatch.distance:关键点之间的距离,越小越好。DMatch.trainIdx:目标图像中描述符的索引。DMatch.queryIdx:查询图像中描述符的索引。DMatch.imgIdx:目标图像的索引。
如果第一名的距离小于第二名距离的 75%,那么将认为第一名大概率是匹配上了,此时 m.queryIdx 为当前帧关键点的索引,m.trainIdx 为上一帧关键点的索引,match_kps 返回的是每对配准点的位置。
for m,n in matches: |
在下图中:红色的是当前帧的关键点,蓝色的是当前帧关键点的位置与上一帧关键点位置的连线。由于 🚗 是向前行驶,因此关键点相对 🚗 是往后运动的。
for kp1, kp2 in zip(frame.curr_kps, frame.last_kps): |

3. RANSAC 去噪和本质矩阵
RANSAC (RAndom SAmple Consensus, 随机采样一致) 算法是从一组含有 “外点” (outliers) 的数据中正确估计数学模型参数的迭代算法。RANSAC 算法有 2 个基本的假设:
- 假设数据是由“内点”和“外点”组成的。“内点”就是组成模型参数的数据,“外点”就是不适合模型的异常值,通常是那些估计曲线以外的离群点。
- 假设在给定一组含有少部分“内点”的数据中,存在一个模型可以估计出符合“内点”变化的规律。
具体的细节这里不再展开,感兴趣的话可以看这里,这里是直接使用三方库里的 scikit-image 里的 ransac 算法进行求解。由于我们在求解本质矩阵的时候,需要利用相机内参将角点的像素坐标进行归一化:
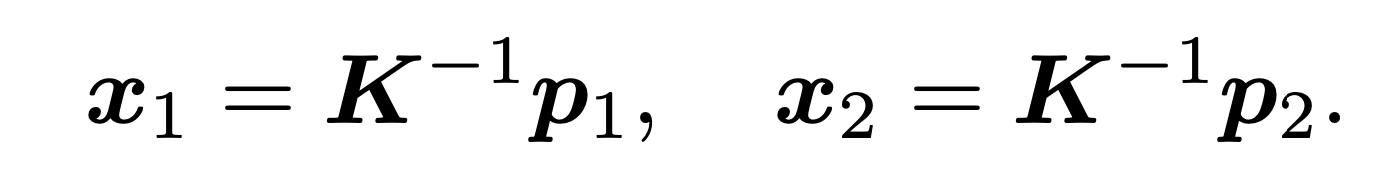
其中 p1 和 p2 分别为配对角点在图片上的像素位置,那么归一化的代码如下:
def normalize(pts): |
slam 知识里给出了本质矩阵和归一化坐标之间的关系,它可以用一个简洁的公式来表达:
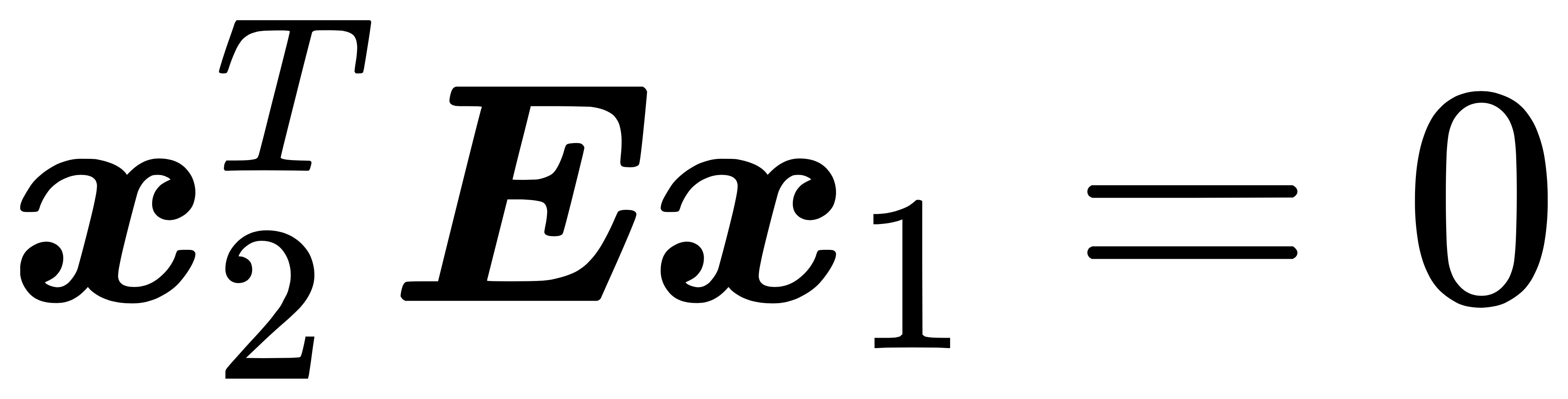
其中本质矩阵 E 是平移向量 t 和旋转矩阵 R 的外积:
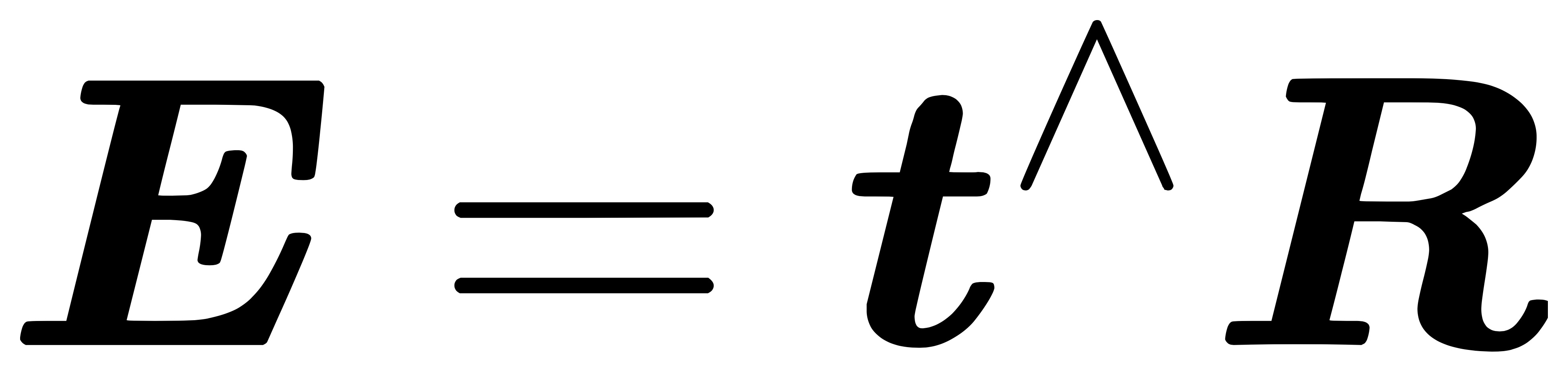
本质矩阵 E 是一个 3x3 的矩阵,有 9 个未知元素。然而,上面的公式中 x 使用的是齐次坐标(已经有一个已知的 1)。而齐次坐标在相差一个常数因子下是相等,因此在单位尺度下只需 8 个点即可求解。

def fit_essential_matrix(match_kps): |

可以看到,经过 RANSAC 去燥后,噪点数据消失了很多,角点的追踪情况基本稳定。但是经过筛选后,角点的数量只有原来的三分之一左右了。
frame: 46, curr_des: 1555, last_des: 1467, match_kps: 549 |
4. 本质矩阵分解
接下来的问题是如何根据已经估计得到的本质矩阵 E,恢复出相机的运动 R,t。这个过程是由奇异值分解得到的:
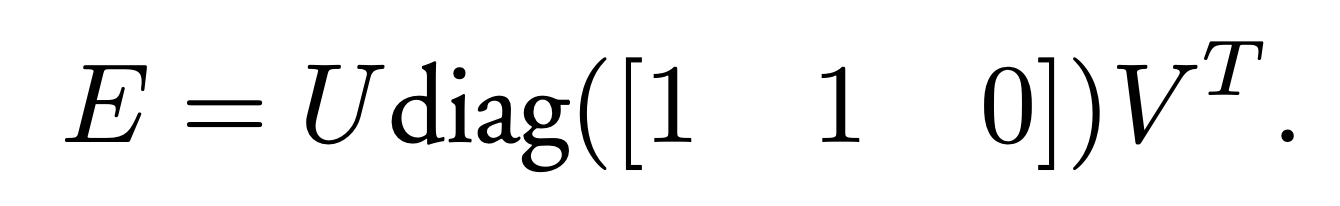
我们发现对角矩阵 diag([1, 1, 0]) 可以由 Z 和 W 拆分得到。
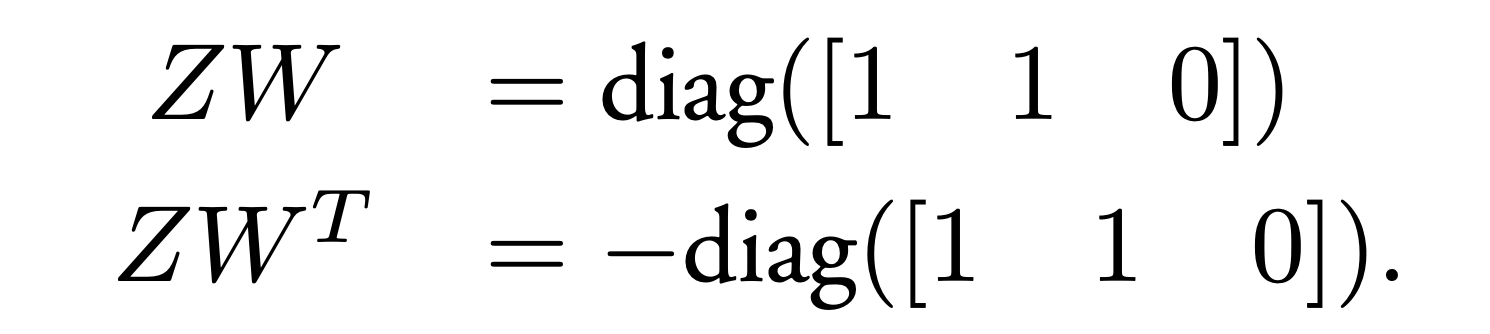
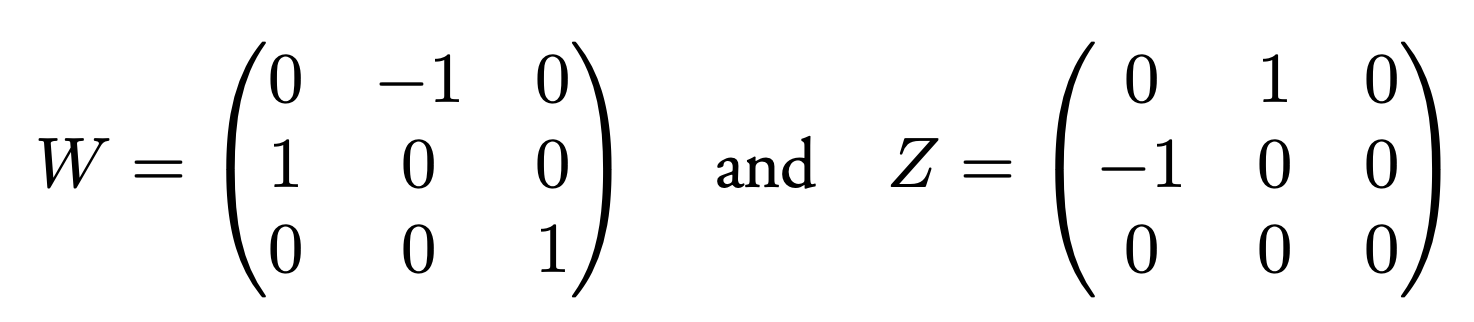
将 Z 和 W 代入进来,令 E = S R。可以分解成两种情况:
- 情况 1:

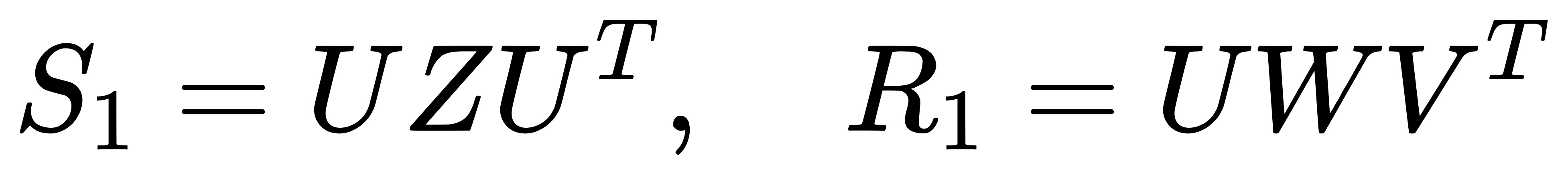
- 情况 2:
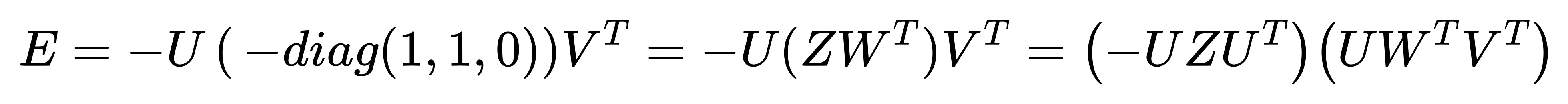
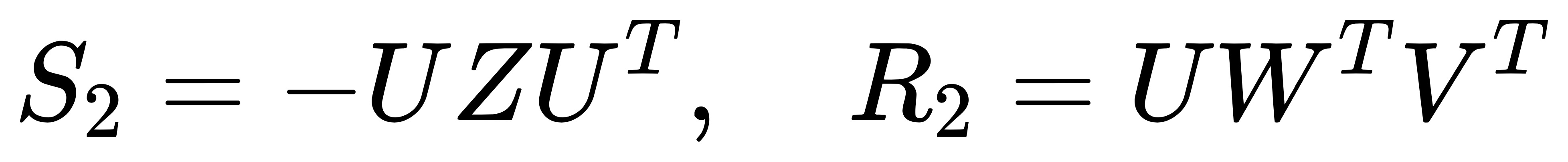
我们发现,此时已经将旋转矩阵 R 分离出来了,它有两种情况:分别等于 R1 和 R2。接下来我们需要考虑平移向量 t,可以证明出 t 其实是在 S 的零向量空间里,因为:

结合线性代数的知识,不难求出 t = U * (0, 0, 1) = u3 (即 U 的最后一列)。考虑到给 t 乘以一个非零尺度因子 λ, 对于 E 而言这种情况依旧有效,而对于 t 而言, 当 λ = ± 1 时,它们物理的意义(方向)却是不同的。综上,在已知第一个相机矩阵 P = [ I ∣ 0 ] 的情况下,第二个相机矩阵 P′ 有如下 4 种可能的解:
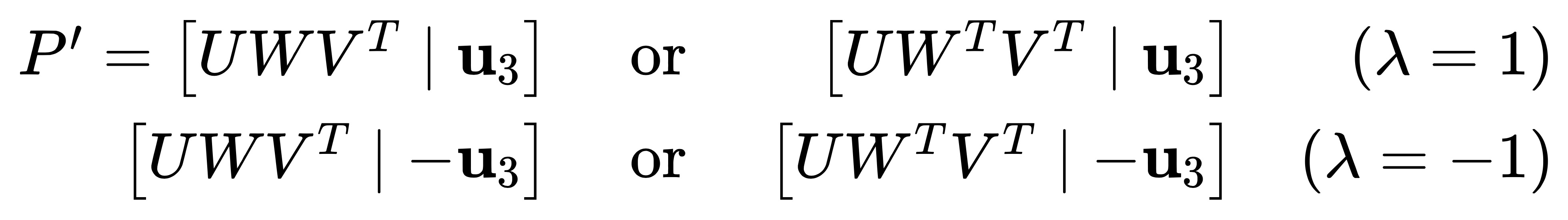
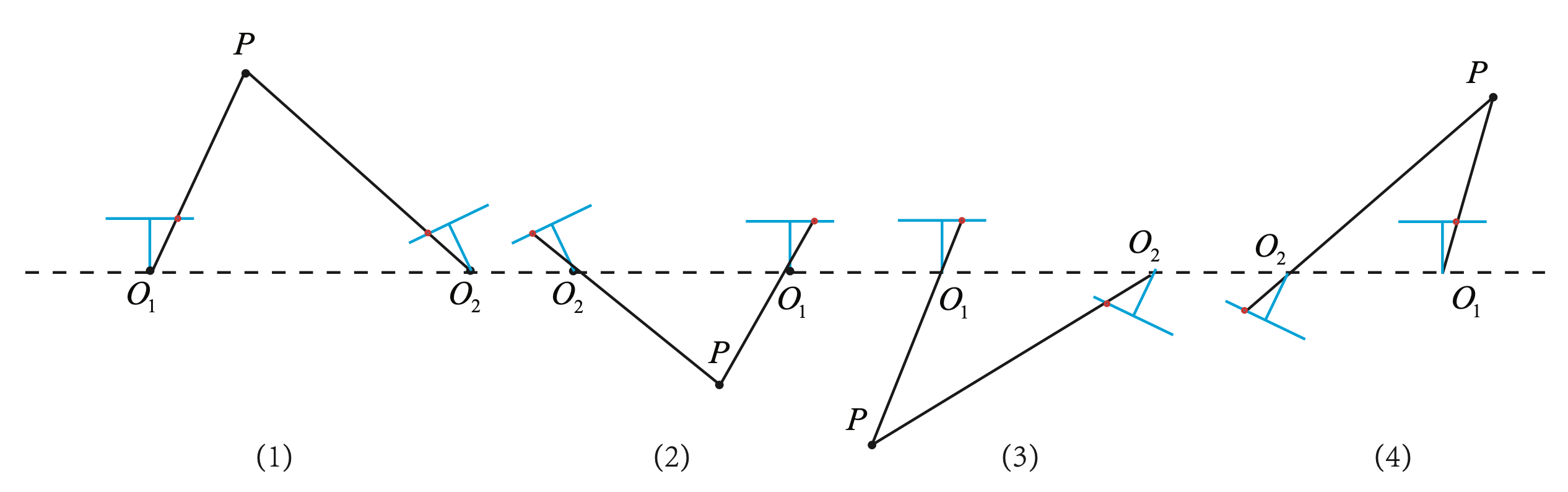
我们发现上面 4 种解其实是 2 种 R 和 2 种 t 之间的排列组合,只有当点 P 位于两个相机前方时才具有正深度,即 (1) 才是唯一正确解。
OpenCV 提供了从本质矩阵中恢复相机的 Rt 的方法:
void cv::decomposeEssentialMat( InputArray _E, OutputArray _R1, OutputArray _R2, OutputArray _t ) |
可以看出 cv::decomposeEssentialMat 函数输出了 R1、R2 和 t,因此 4 种可能的解分别为:[R1,t], [R1,−t], [R2,t], [R2,−t], ORB_SLAM2 里使用了 CheckRT 函数对它们进行判断。考虑到 demo 视频里 🚗 是一直往前行驶,且没有转弯。因此相机 t = (x, y, z) 里的 z > 0,并且相机 R 的对角矩阵将接近 diag([1, 1, 1]) ,从而我们可以直接过滤出唯一解。
def extract_Rt(E): |
由于平移向量的分量 t[2] > 0,我们很容易知道 Rt 为从相机坐标系的位姿变换到世界坐标系的位姿
5. 三角测量
下一步我们需要用相机的运动估计特征点的空间位置,在单目 SLAM 中仅通过单目图像是无法获得像素的深度信息,我们需要通过三角测量(Triangulation)的方法估计图像的深度,然后通过直接线性变化(DLT)进行求解。

假设点 P 的世界坐标为 X_{w},图像坐标为 X_{uv},相机的内参和位姿分别为 K 和 P_{cw},那么得到:
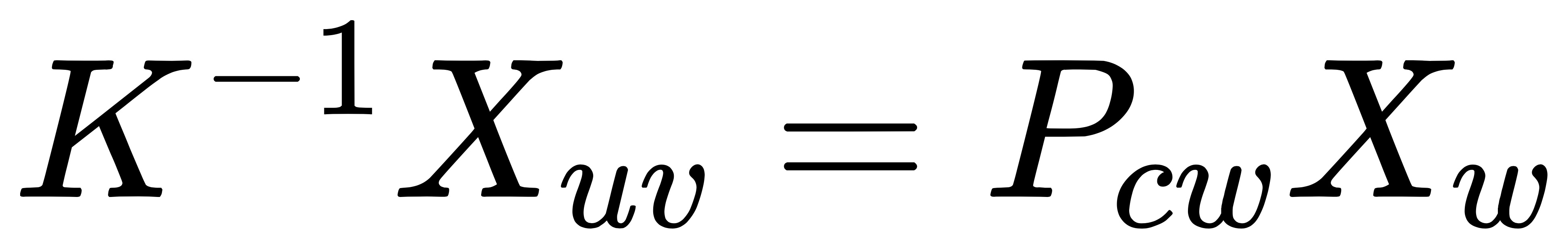
将下标去掉,使用相机内参将两个匹配的角点像素坐标进行归一化,代入到上述方程中便得到:
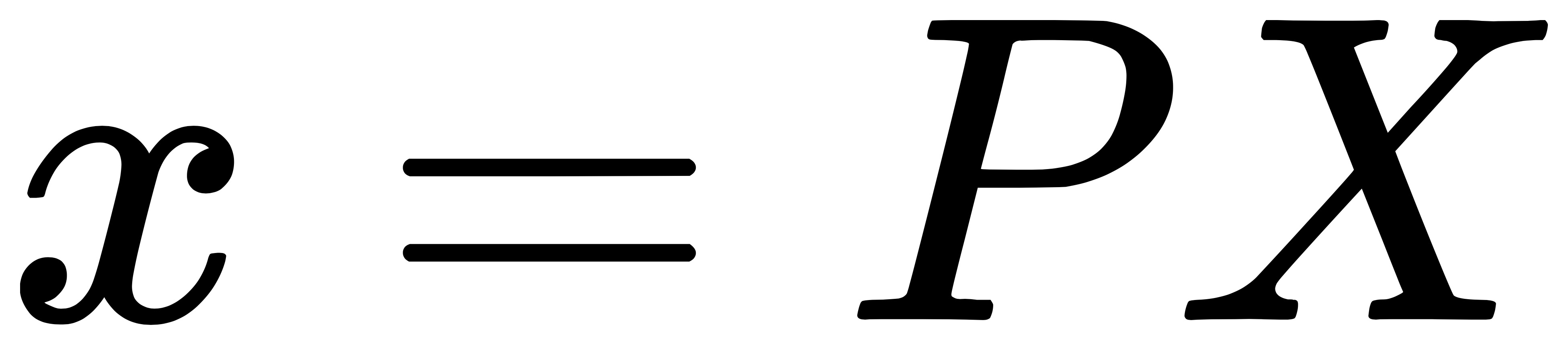
使用 DLT 的话我们对上面两个公式进行一个简单的变换,对等式两边分别做外积运算:

由于 x={u, v, 1} ,结合外积运算的知识(详见 slam 十四讲 75 页),我们便得到以下方程:
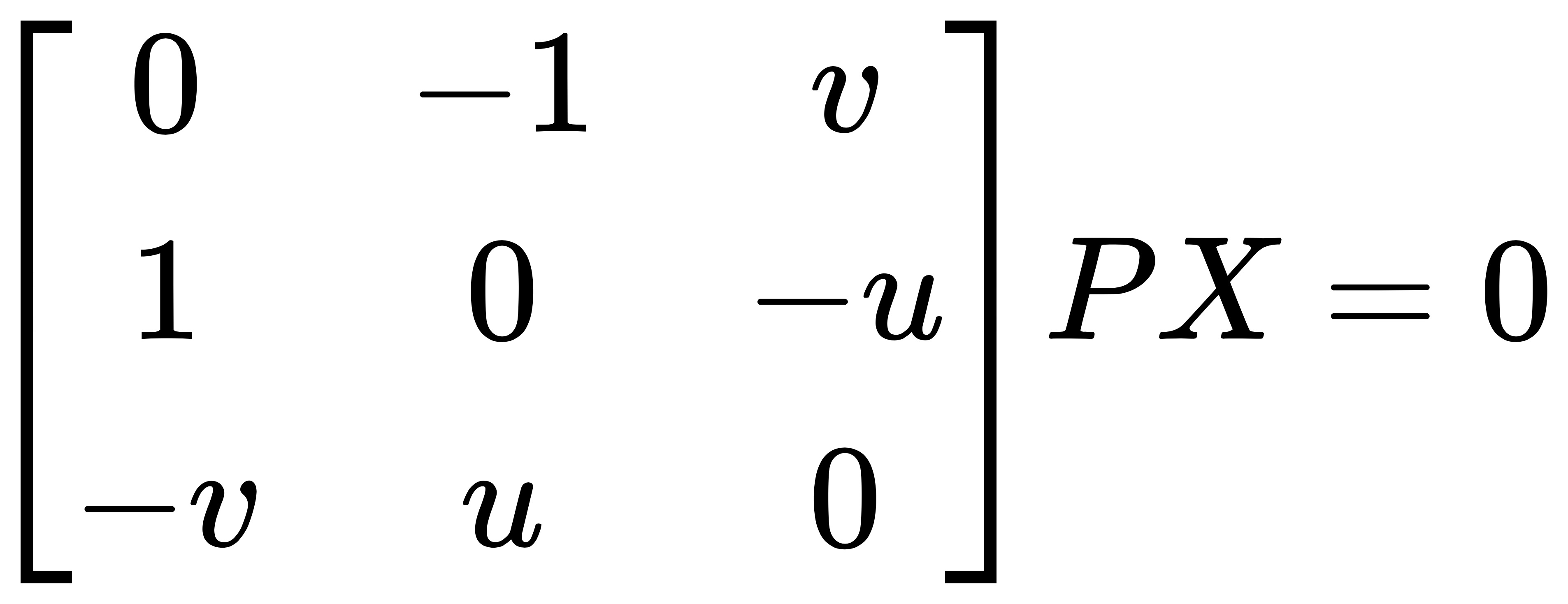
我们不妨令:
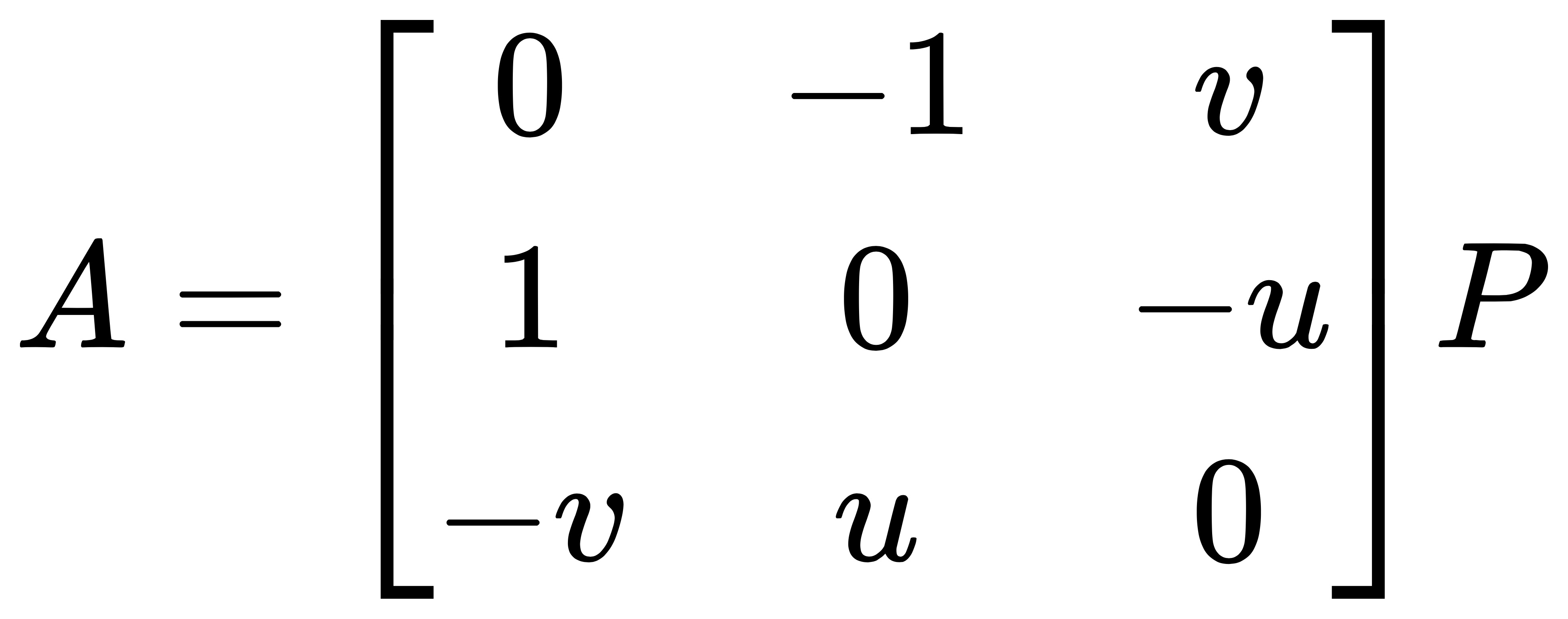
将两个匹配的角点和相机位姿代入上述方程中便得到 A:
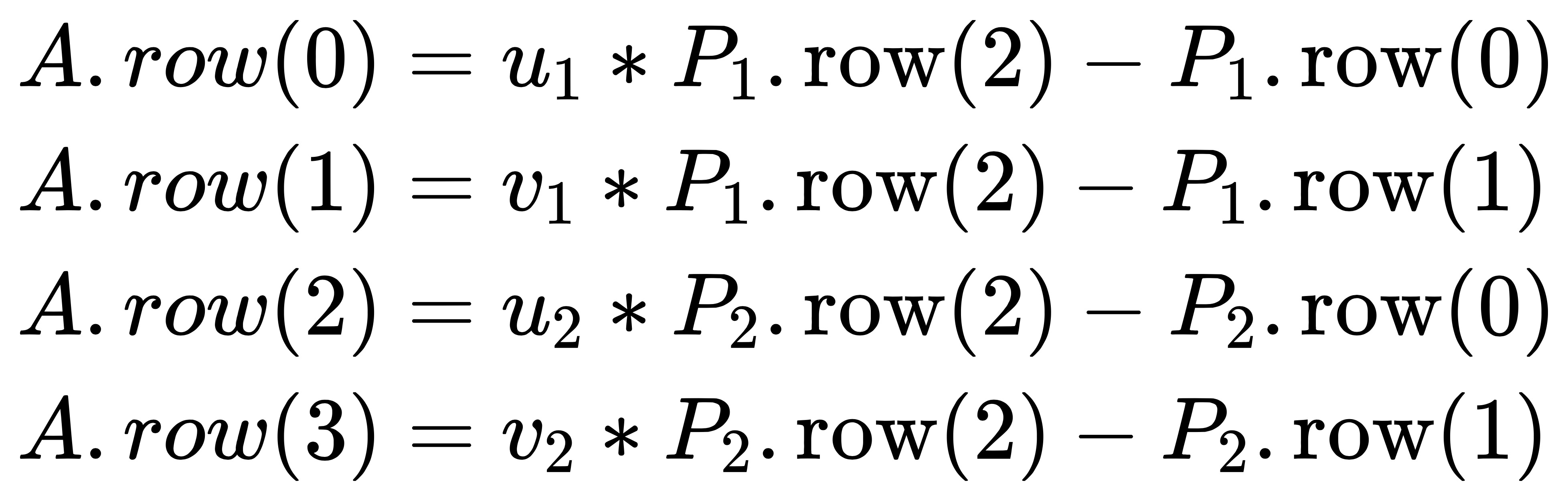
因此便可以简化成 AX=0,从而可以使用最小二乘法来求解出 X,ORB_SLAM2 中的求解过程如下:
void Initializer::Triangulate(const cv::KeyPoint &kp1, const cv::KeyPoint &kp2, const cv::Mat &P1, const cv::Mat &P2, cv::Mat &x3D) |
如下所示,我使用了 Python 对整个三角测量的计算过程进行了复现。值得注意的是,上述的相机位姿是指从空间点 P 从世界坐标系变换到相机坐标下点变换矩阵。如果你不清楚相机位姿的概念,请看什么是相机位姿?
def triangulate(pts1, pts2, pose1, pose2): |
6. pipeline 流程
def process_frame(frame): |