全卷积神经网络(FCN)
在我还是实习生的时候,我们组的 leader 讲了 FCN 网络。由于当时对图像分割还不是很了解,所以也没太听懂,只记得他当时讲这篇文章拿了 CVPR-2015 的最佳论文奖。现在学习 FCN 就觉得,这应该是图像分割领域里最经典也是最适合入门的网络了吧。
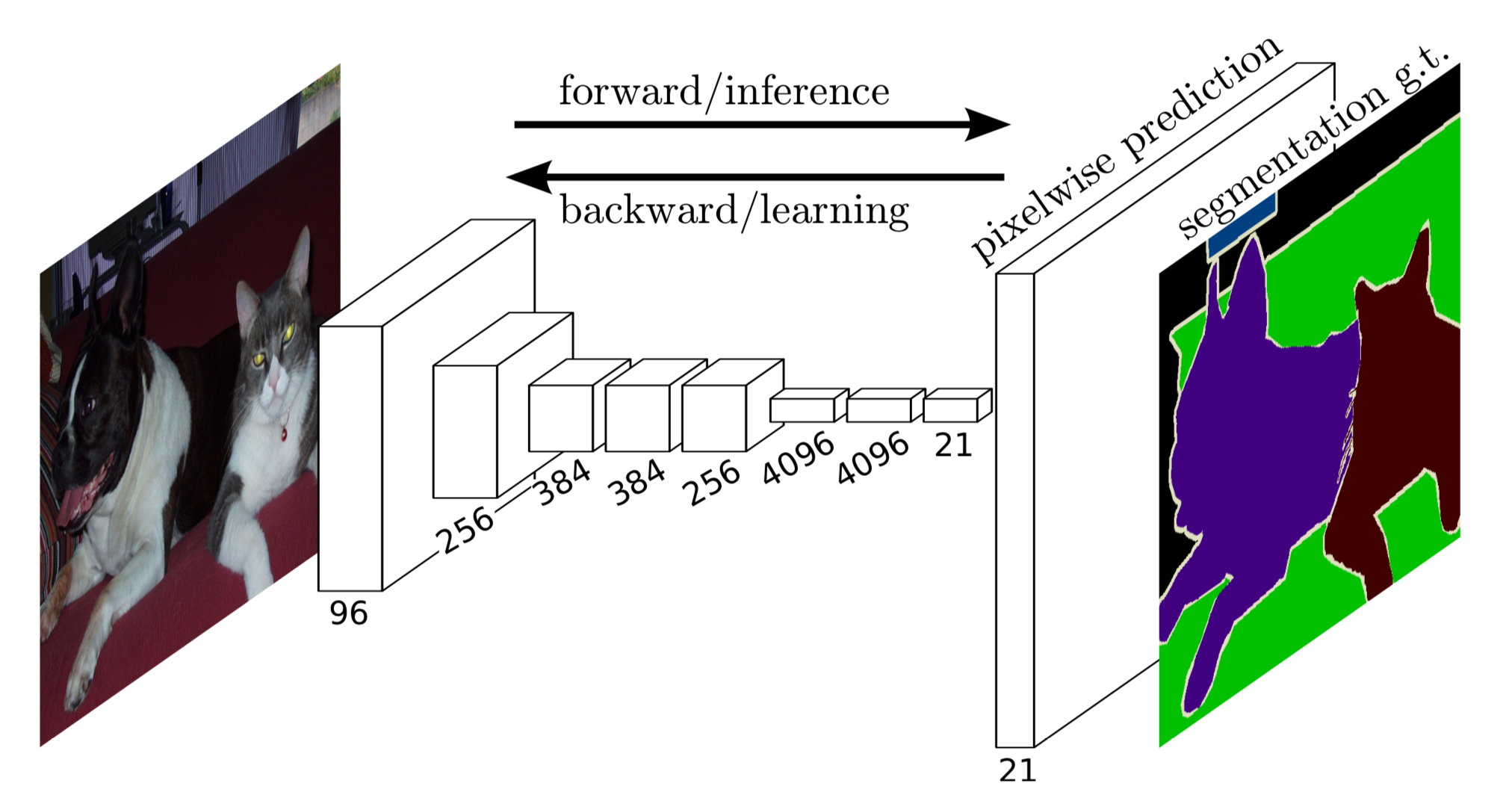
1. 分割思想
在我的代码里,使用了 VGG16 作为 backbone 来提取图片特征(其实作者也使用了 VGG19 作为backbone,但是发现效果和 VGG16 差不多)。如果把 FCN 看成是一个黑箱子,那么我们只要关心网络的输入和输出就行了。如果我们使用 VOC 数据集进行训练,输入图片的维度为 [H,W,C],那么 FCN 输出的 feature map 形状则为 [H, W, 21]。其中,数字 21 代表的 VOC 的 20 个类别还有 1 个背景。
FCN 解决的实际问题就是针对图片里的每个像素进行分类,从而完成精确分割。按照以往 CNN 解决分类问题的思路,一般都会在 feature map 后面接一个全连接层,这个全连接层应该有 21 个神经元,每个神经元输出各个类别的概率。但是由于全连接的特征是一个二维的矩阵,因此我们在全连接层之前会使用 Flatten 层将三维的 feature map 展平。这就带来了2个问题:
- 使用了 Flatten 层抹平了图片的空间信息;
- 一旦网络训练好,图片的输入尺寸将无法改变。
FCN 网络很好地解决了这两个问题,它可以接受任意尺寸的输入图像,并保留了原始输入图像中的空间信息,最后直接在 feature map 上对像素进行分类。
2. 跳跃连接
在刚开始的时候,作者将输入图片经过卷积和下采样操作一头走到尾,最后宽和高都被缩放了 32 倍。为了将 feature map 上采样到原来的尺寸,因此作者将 vgg16 的输出扩大了 32 倍,并将该模型称为 FCN-32s。
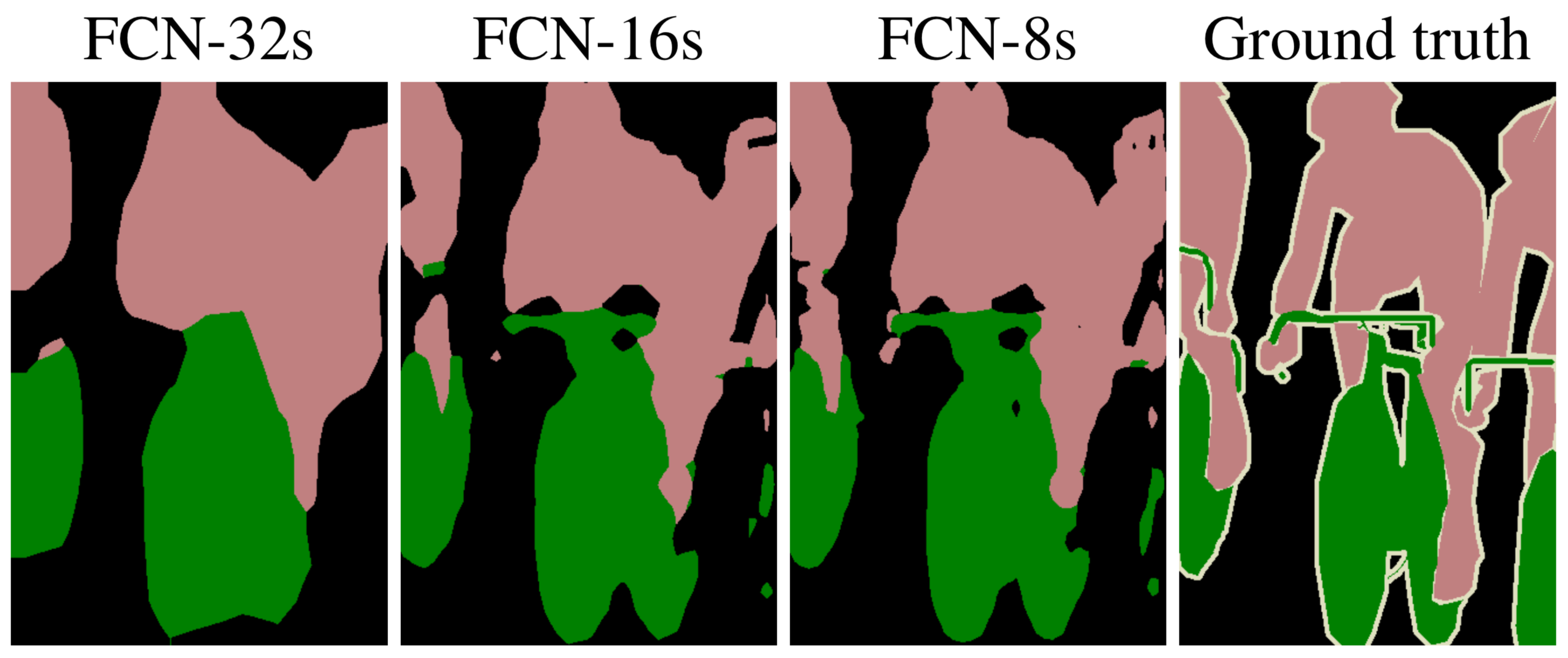
但是发现FCN-32s的分割效果并不够好,如下图所示。尽管最后的 feature map 输出经过了 32 倍的上采样操作,但是图片里的边缘细节信息还是被 VGG16 网络里的卷积和下采样操作所模糊掉了。
作者把它称作是一个what和where的问题,请看下面作者的原话:
Semantic segmentation faces an inherent tension between semantics and location: global information resolves what while local information resolves where.
说白了就是全局信息能够预测这个物体是哪个类别,而局部的细粒度信息能够实现对物体的定位与检测。为了解决这个问题,作者通过缓慢地(分阶段地)对编码特征进行上采样,从浅层添加了“skip connections(跳跃连接)”,并将这两个特征映射相加,并最终将它上采样 8 或者 16 倍进行输出,分别称为 FCN-8s 和 FCN-16s 模型。
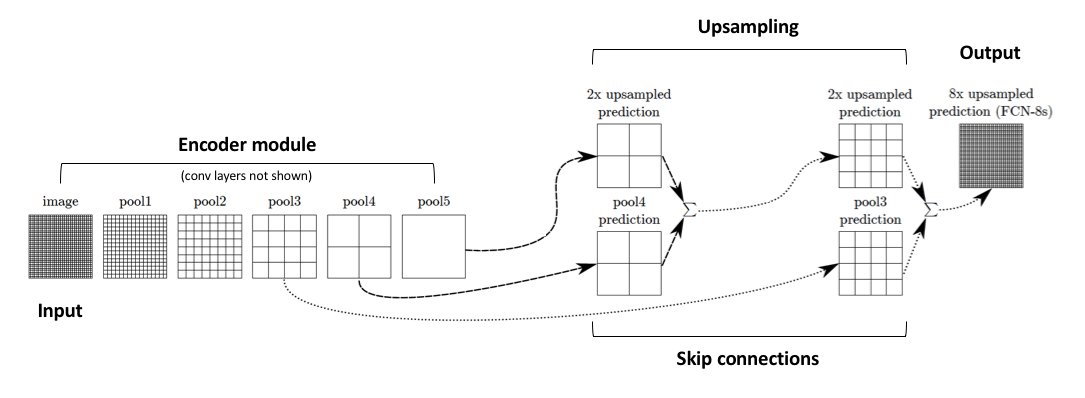
添加 skip connections 结构后,就能将深层的,粗糙的语义信息与浅层的,精细的表面信息融合起来,从而在一定程度上解决图像边缘分割效果较差的问题。
We define a skip architecture to take advantage of this feature spectrum that combines deep, coarse, semantic information and shallow, fine, appearance information
这里需要抛出一个问题,为什么这个 “跳跃连接” 这么牛逼有效?
这还得从感受野(Receptive Field)说起,卷积神经网络中感受野的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入原来图片上的区域。
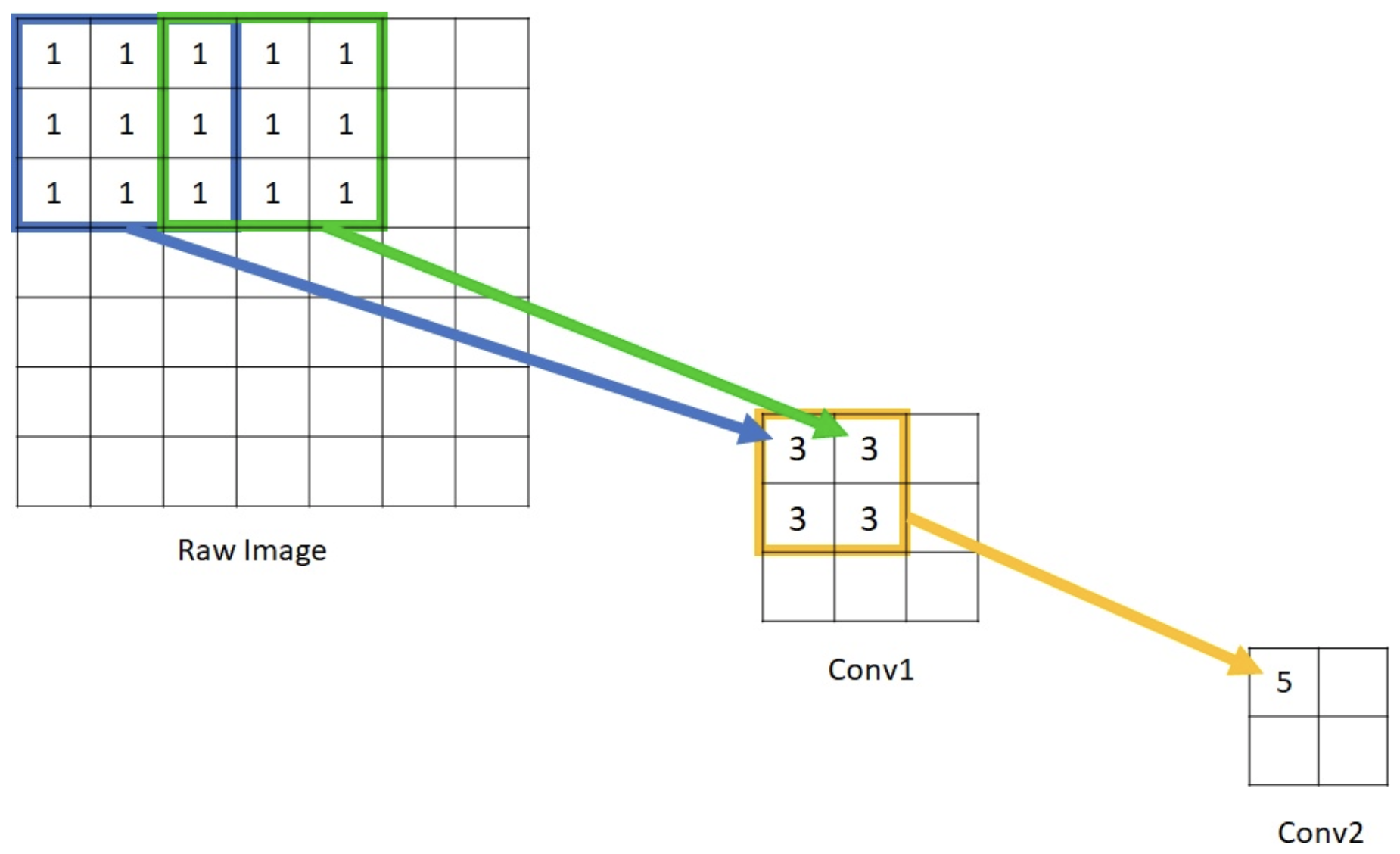
前面讲到深层的特征图在空间尺寸上往往会越来越小,这就意味着它的感受野区域会越来越大,从而更富含图片的全局信息,能较好地解决 what 问题;浅层特征图的空间尺寸较大,这就意味着它的感受野会更小,因而容易捕捉到物体的边缘信息和丰富的细粒特征,能较好地解决 where 问题。感受野大的特征,可以很容易的识别出大物体的,但是在实际分割中,大物体边缘信息和小物体本身是很容易被深层网络一次次的降采样和一次次升采样给弄丢的,这个时候就可能需要感受野小的特征来帮助。
在上图中,如果把 conv1 和 conv2 分别比作浅层特征和深层特征的话。那么深层特征里一个数字 “5” 的感受野尺寸就是 3x3,而浅层特征里 4 个 数字 “3” 的感受野也是这个区域,但是平均下来 1 个数字 “3” 的感受野尺寸则 1x1 都不到。
深层特征的感受野较大,浅层特征的感受野较小,它们分别解决 what 和 where 问题。反正如果将它们联合起来,那就牛逼了!
3. 反卷积层
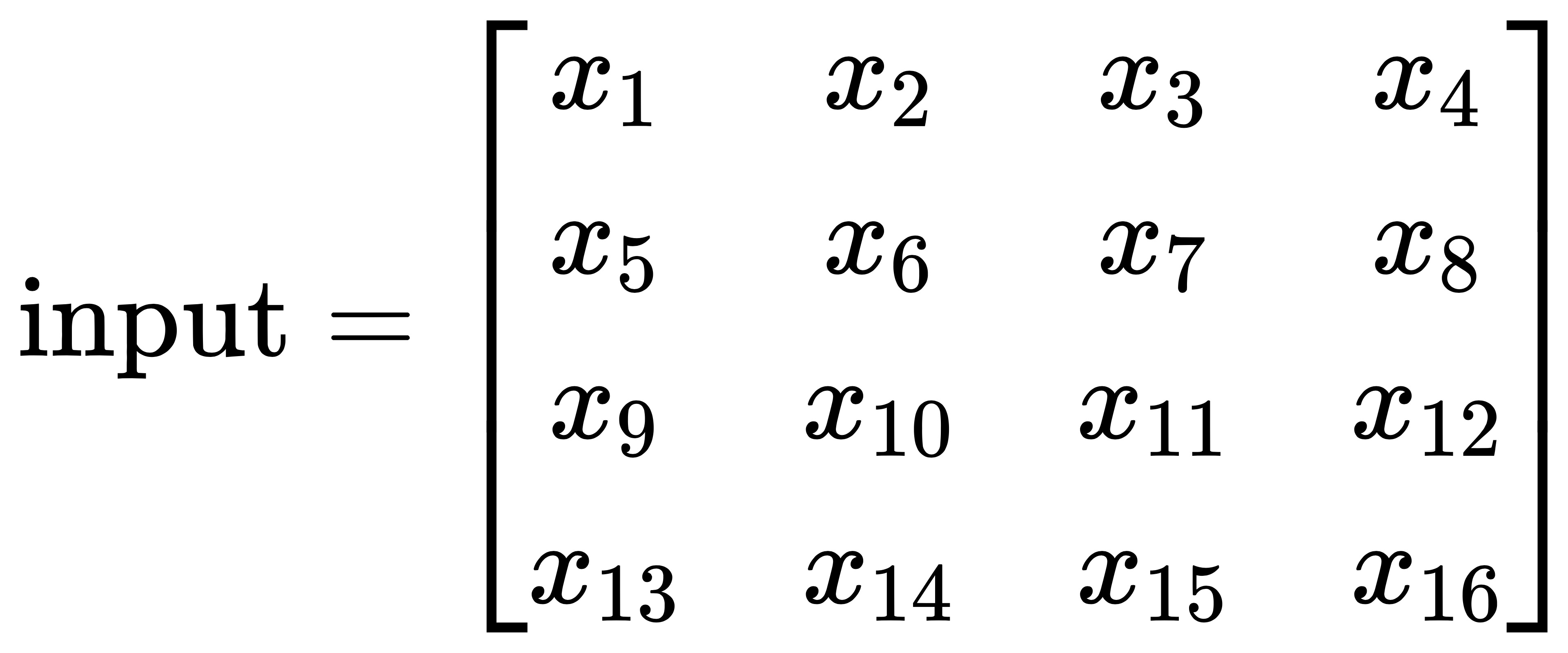
FCN的上采样层使用的是反卷积层,反卷积也称为转置卷积操作(Transposed convolution)。要了解反卷积是怎么回事,得先回顾一下正向卷积的实现过程。假设输入的图片 input 尺寸为 4x4,元素矩阵为:
卷积核的尺寸为 3x3,其元素矩阵为:
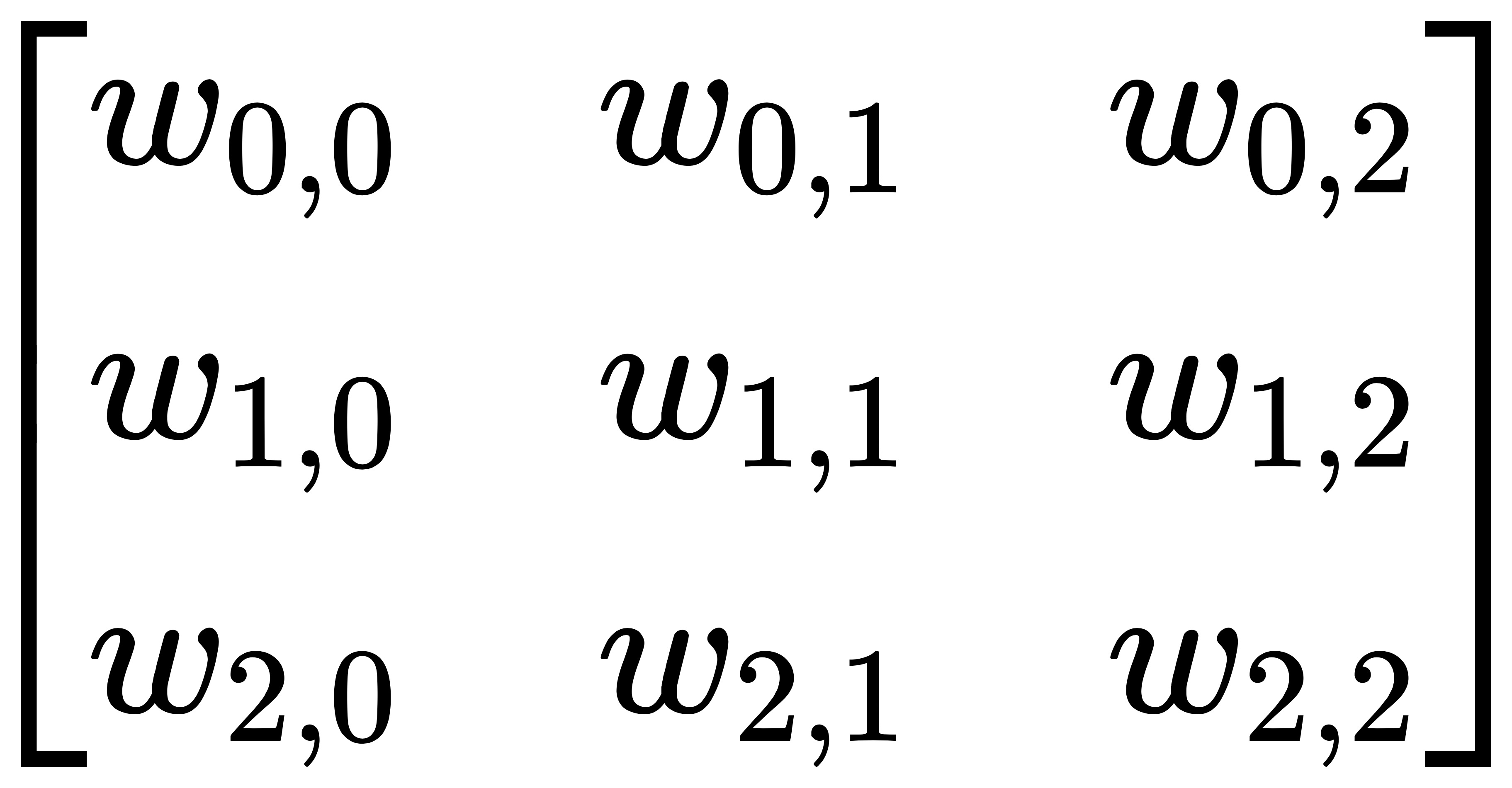
正向卷积操作:步长 strides = 1, 填充 padding = 0,输出形状为 2x2,该过程如下图所示:

在上面这幅图中,底端为输入,上端为输出,卷积核为 3x3。如果我们用矩阵乘法去描述这个过程: 把 input 元素矩阵展开成一个列向量 X

把输出图像 output 的元素矩阵展开成一个列向量 Y
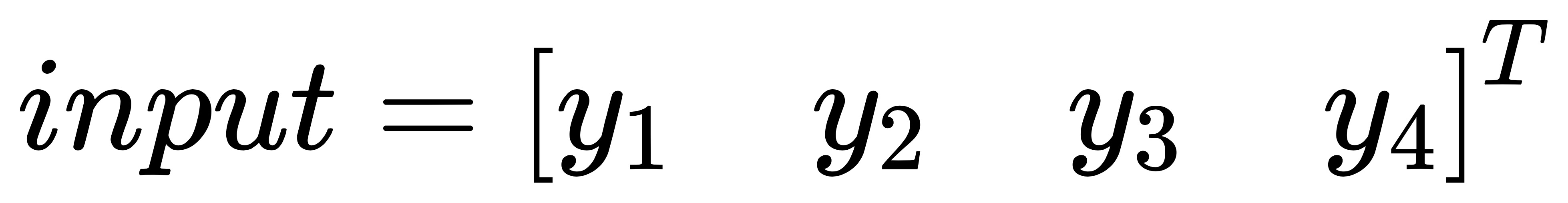
对于输入元素矩阵 X 和输出元素矩阵 Y ,用矩阵运算描述这个过程:
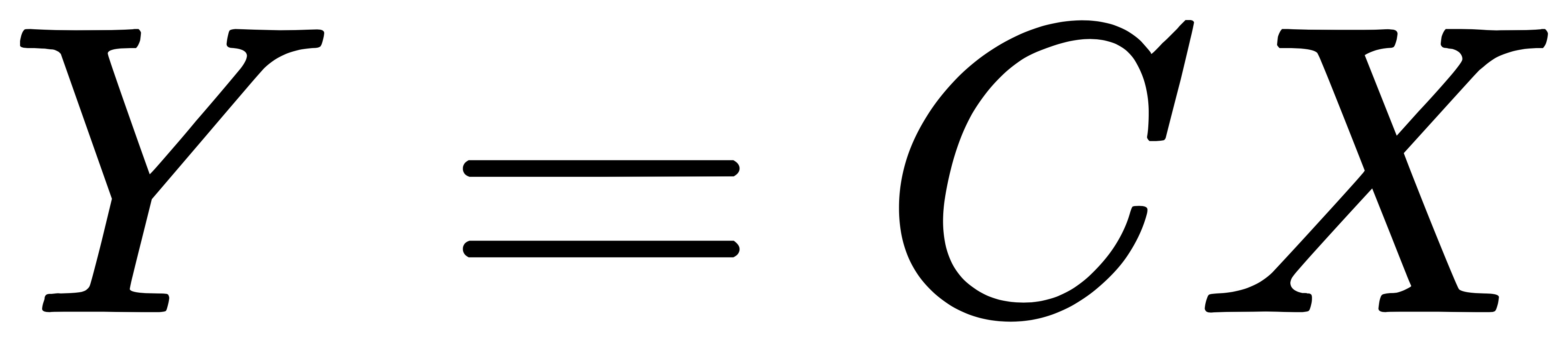
通过推导,我们可以获得稀疏矩阵 C
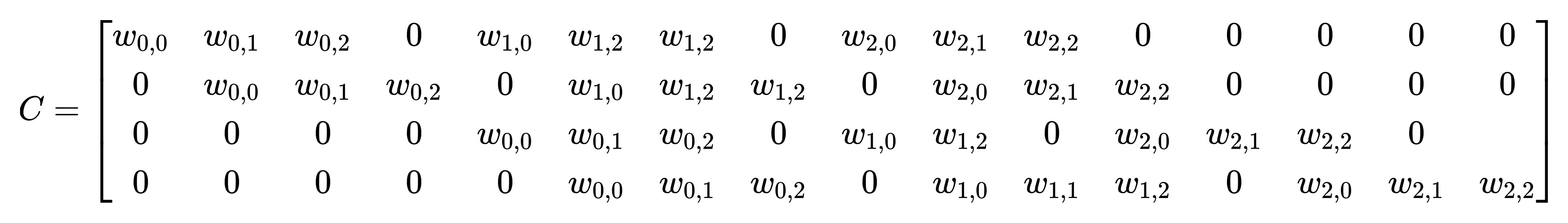
稀疏矩阵 C 的形状为 4x16, X 形状为 16x1,Y 的形状为 4x1,将 Y 进行 reshape 后便是我们的期望输出形状 2x2。那么,反卷积的操作就是要对这个矩阵运算过程进行转置,通过输出 Y 得到输入 X:
从矩阵元素形状的角度出发,可以理解为:16x1=16x4x4x1,下面这个动画比较生动地描述了反卷积过程:
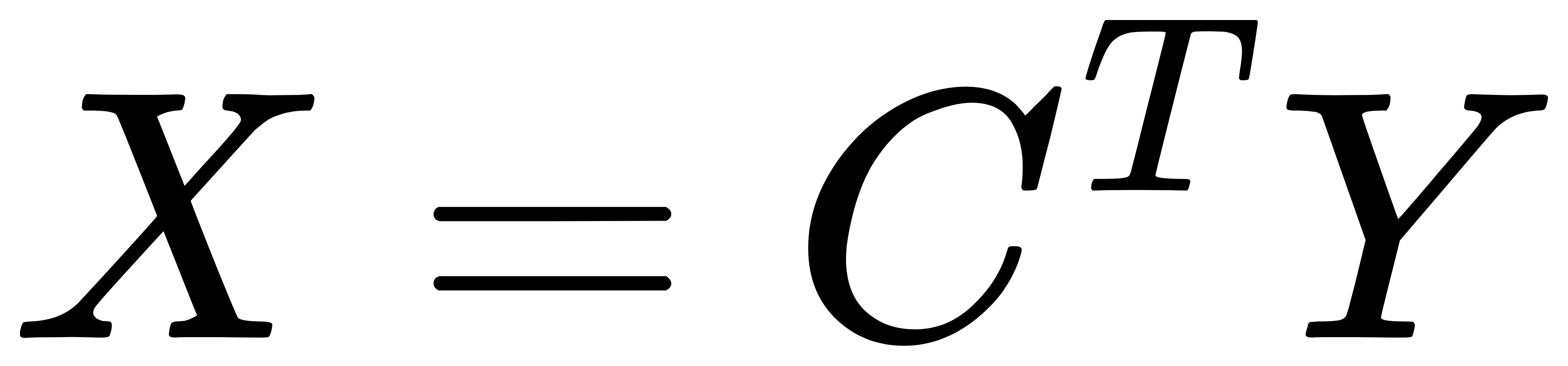
值得注意的是,反卷积操作并不是卷积操作的可逆过程,也就是说图像经过卷积操作后是不能通过反卷积操作恢复原来的样子。这是因为反卷积只是转置运算,并非可逆运算。
4. 数据处理
在 PASCAL VOC 数据集中,每个类别对应一个色彩【RGB】, 因此我们需要对SegmentationClass文件夹里的每张 mask 图片根据像素的色彩来标定其类别,在代码 parser_voc.py是这样进行处理的。
for i in range(H): |
考虑到在批量训练图片时的 batch_size >= 1,因此必须将图片 resize 成相同的尺寸,这里采用的是最近邻插值法,从而保证新插值的像素分类问题。
5. 模型训练
如果你要训练 FCN-8s 的话,还是推荐你加载 VGG16 模型的,否则会变得非常耗时。还有一点的就是,其实训练图片里的像素类别是非常不均衡的。例如 75% 的图片像素都属于背景(见上图),因此你会发现在训练时其精度很快就达到了80%,但此时的预测结果却是一片黑,即预测的类别都为背景。
一般对于语义分割的训练,学术界有两种办法: Patchwise training 和类别损失加权的方法来进行训练。
- Patchwise training: 补丁式训练方法,它旨在避免全图像训练的冗余。在语义分割中,由于要对图像中的每个像素进行分类,如果输入整个图像可能会有大量的冗余。因此在训练分割网络时,避免这种情况的一种标准方法是从训练集而不是完整图像中给网络提供成批的随机补丁(感兴趣对象周围的小图像区域)。从另一种角度出发,我们也可以使得这些补丁区域尽量减少背景信息,从而缓解类别不均衡问题。
- 类别损失加权: 根据类别数量的分布比例对各自的损失函数进行加权,比如有些样本的数量较少,我就给它的损失函数比重增大一些。
对此,作者根据实验结果非常霸气地放话了:
explore training with sampling in Section 4.3, and do not find that it yields faster or better convergence for dense prediction. Whole image training is effective and efficient.
补丁式训练完全没有必要,训练 FCN 还是输入整张图片比较好。并且解决这种类别不均衡的问题,只需要给损失函数按比例加权重就行。最后作者还对此进行了学术上的解释,我这里就不讲了,话讲多了你们会觉得我在胡言乱语…
参考文献
- [1] Jonathan Long, Evan Shelhamer, Trevor Darrell. Fully Convolutional Networks for Semantic Segmentation. CVPR 2015
- [2] TensorFlow2.0-Example code: FCN